Chapter 12 Deep Learning - Learn Tasks End-To-End
- Deep learning uses neural networks with many layers.
- Deep learning enables end-to-end learning: replace multiple steps with just 1 neural network.
- The mindset allows to custom-build a network layer by layer for an application.
- This way of modeling allows embeddings and fine-tuning.
- Deep learning is a machine learning mindset independent of supervised, unsupervised and reinforcement learning.
The statistician watched in horror as the deep learner kept adding more and more layers to his model. The model was a monstrosity, she had never seen anything like it. No theory about the data, no guarantees, just millions of parameters.
In 2013, I used a neural network for the first time. A small neural network with two hidden layers. It was disappointing. Training was slow (admittedly on a CPU) and performance was underwhelming. Trying the the neural network was part of a machine learning class in university. Just another supervised learning method I learned about, on the same level as decision trees, support vector machines and k-means.
Little did I know at the time that the rebirth of “artificial neural networks” was in full swing. Deep neural networks had already started to crush the competition in image recognition tasks like the ImageNet image classification challenge (Russakovsky et al. 2015) or a traffic sign recognition challenge (Cireşan et al. 2011). In 2022, the year this text is written, the hype is still going strong or even stronger. The trick seemed to be to give the networks more layers, to make them “deeper”. And so artificial neural networks have evolved to deep learning.
12.1 Is Deep Learning A Mindset?
Technically, deep learning is “just” neural networks with many layers.
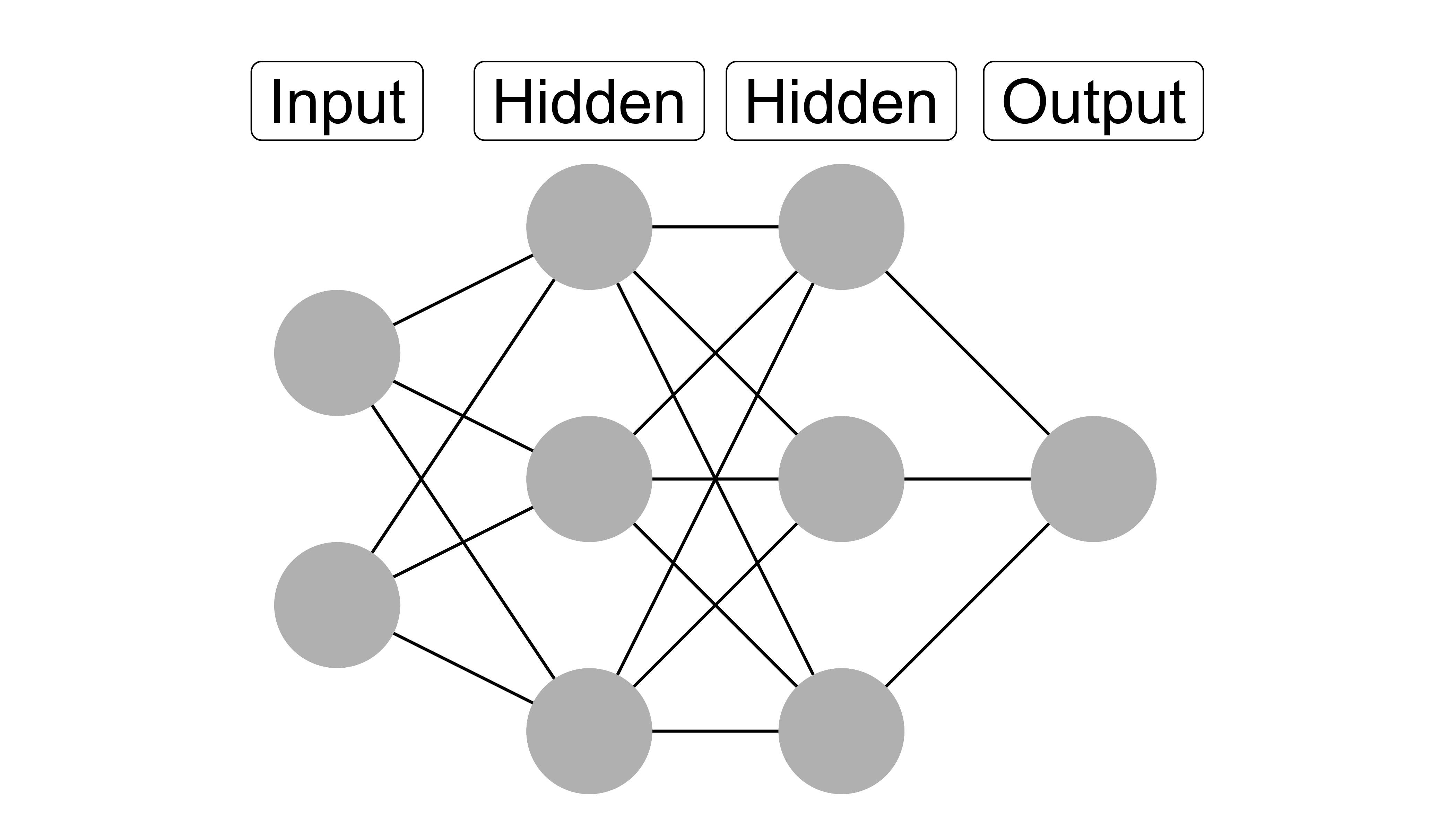
FIGURE 12.1: A neural network with two input features, a first hidden layer with 3 neurons, another hidden layer with 3 neurons, and a single output.
A neural network13 takes input data (images, tabular data, …) and produces an output such as a classification score. The atomic units of the network are neurons (and weights), but it’s more useful to think of layers as the basic units. The output of each layer serves as the input to the next layer. The input data is transformed multiple times as it travels through the layers of the neural network. In each step the data undergoes a mathematical transformation. These mathematical transformations are parameterized. Take a fully connected layer: The activation of a neuron is a weighted sum of the neurons from the previous layer.
Training a neural network means finding a weight configuration for the layers that minimizes a loss function. Neural networks are usually trained using stochastic gradient descent: Data is fed to the network in batches for which the network output is received and the loss calculated. The derivative of the loss is traced back through the network in a process called backpropagation. This derivative with the respect to the parameters indicates how to change the parameters to improve the output of the model (in terms of loss). The parameters are changed slightly in this direction, and learning continues with the next data batch.
I could have written a similar introduction to SVMs or random forests, but I wouldn’t claim that a new modeling mindset emerges from them. So why say that deep learning is an mindset? I think deep learning is a mindset, but its origin is a little different from the other mindset. Usually a mindset comes first and serves as framework for the methods. For deep learning, the methodology comes first, but a mindset emerges from properties deep networks. Not everyone might agree to this view, but I think it’s worthwhile to see deep learning as a mindset.
Deep learning is a mindset because of the following properties:
- Deep learning encourages to model tasks end-to-end: from raw data to the final outcome. No feature engineering, model comparisons, complex pipelines, …
- An emergent behavior of neural networks is embedding: Within the learned weights of neural network, useful information is stored which can be used in feature engineering (e.g. word embeddings), to kick-start other neural networks or learn the information (activation maximization).
- Deep learning comes with a high modularity which makes it possible to custom-build a model for a use case.
- Deep learning has a huge research community that only does neural network.
- Deep learning works incredibly well for text, images and audio.
- There is a lot of specialized hardware and software for deep learning.
All these properties make deep learning a coherent framework for modeling, one that is somewhat self-contained: The modeler doesn’t have to “leave” neural networks to solve a task. Deep learning has its center of gravity.
But a modeler can totally use neural networks just as a model within another mindset. I want to distinguish neural networks as a method and deep learning as a mindset with the following story:
Tom and Annie have to classify product reviews as “positive” or “negative”. Tom applies a pure supervised mindset and start with feature engineering: Bag-of-words which counts the occurrences of each word, removing words like “and”, reducing words to word stems, … just classic tasks in natural language processing. Since there are too many features, tom uses LASSO (a linear model) for feature selection. Based on this dataset, Tom compares various machine learning models and picks the best performing one which happens to be a random forest.
Annie has a deep learning mindset. Because of that she thinks about an end-to-end learning approach: Input the raw text, produce the classification. She can skip all the feature engineering and stuff, because all this happens within her neural network. But her network has trouble to learn – 3000 reviews turn out to be too little for the network to learn the data. Instead of going Tom’s approach, she seeks out a deep learning solution: She takes word embeddings from a neural network that was trained on a larger corpus of text and incorporates it into her neural network. Now she can train her model end-to-end: one neural network connecting raw text input to the predicted class.
Tom and Annie get a new requirement: Integrate images that customer took into the model. Tom tries two approaches: the first is to extract features from the images such as color histograms and edge detectors, which he feeds into different supervised models to predict the outcome. The other approach is to use a convolutional neural network to classify the review. He decides for the latter as it performs better. Then he uses the classification of the neural network in his random forest. Annie translates the new requirement into an adaption of the current network architecture: She adds images as additional input to the current neural network, followed by some convolutional layers, and the embeddings are then combined with the word embeddings which are followed by fully connected layers to produce the categorization. She later uses the embeddings learned by her model for other tasks, such as clustering reviews. Just when Tom and Annie thought they can relax, their demanding boss gives them yet another task: Predict whether a review will be considered helpful by others (for which there is labeled data). Tom builds a new model (although he reuses parts of his current pipeline). Annie adapts the neural network so it has two outputs: positive/negative and helpful yes/no. She also uses the embeddings of the neural network for the reviews for other tasks such as clustering.
Tom and Annie used similar methods, in parts. However, Annie used a deep learning first approach, and tried to model everything end-to-end with neural networks. End-to-end learning is made possible by the “Lego”-like modularity of neural network layers.
12.2 Stacking Lego Bricks
Lego is a construction toy system for kids and adults. Lego bricks can be combined into larger structures such as a castle, a horse, or a space shuttle. Deep learning has layers instead of bricks. These layers can be freely combined, as long as input and output dimensions match. Different layers have different purposes:
- Fully connected layer. All neurons in the previous layer are connected to all neurons in the next.
- Convolution layer. Creates regional image-like feature maps for grid-like data such as images or spatial data.
- Embedding layer. Converts categorical data such as words or colors into numeric vectors which relate the categories to each other.
- …
There is a huge amount of layer types available for various tasks, data types and goals. This arsenal of layer types allows the modeler to customize a neural network for any task. That’s why neural networks for so many different data types, from videos, to tabular data and sensor data. The modeler can create neural networks with more than one output, or with different types of data input, for example a mix of image and text as in the example.
The glue that holds a neural network together and allows it to still be trained is the gradient. As long as for each layer the gradient of the loss can be computed, the modeler can stack the layers to their liking. Most modern deep learning software packages have auto-gradient abilities and also built-in gradient-based optimization routines. By picking the right loss function, the right last layer, and a respective evaluation method, the neural network can be used for any task: From classification, regression and word embeddings to image segmentation, survival analysis, and deep reinforcement learning. The modelers don’t have to leave the world of neural networks to solve a task. Other algorithms, such as random forests, are not as flexible.
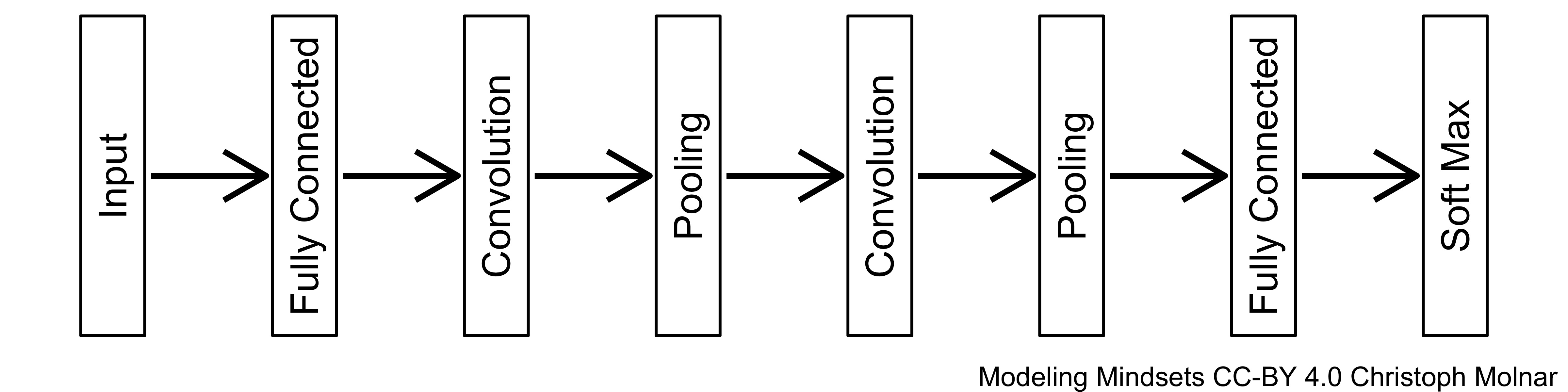
FIGURE 12.2: Deep learning allows to stack layers.
12.3 Emerging Properties
Curious thinks happen when a modeler trains a neural network end-to-end: The network might learn to create it’s own features within the neural network, which are stored as activations in the layers. This emergent property of neural networks is more than just a fun fact – representation learning gives rise to a style of modeling that is special to deep learning. Let’s take a look at convolutional neural networks (CNNs) used for image classification. CNNs learn to recognize certain spatial patterns in images. The first layer learns to recognize edges in different directions. The second layer learns to recognize simple patterns. The more layers the data has moved through, the more complex the recognized patterns become. Even concepts like flowers and dog faces can be recognized, see Figure 12.3.

FIGURE 12.3: Features learned by a convolutional neural network (Inception V1) trained on the ImageNet data. Features range from simple edge detectors in the lower convolutional layers (left) to more abstract concepts in the higher convolutional layers (right). Figure from Olah, et al. (2017, CC-BY 4.0) https://distill.pub/2017/feature-visualization/appendix/.
Models that are trained on huge amounts of data often have learned very useful and general feature representations. Deep learning modelers leverage these pre-trained models in various ways:
- Fine-tuning: Freeze the weights of the neural network, except for the last layer, and train only this last layer. There are various variations such as using the weights of the pre-trained network as weight initialization and then training on your own task.
- Embeddings: Use the pre-trained network as data pre-processing step. Input the data into the pre-trained network, but don’t push it all the way through; instead extract a tensor from a layer between input and output, usually just before the output. Use this feature representation instead of the original features for your next modeling steps. This is actually quite similar to fine-tuning.
- Simplify: Keep the pre-trained model, but modify the output. Need a classifier for cat vs. dog? Just take a pre-trained image classification model, but work only with the probability output for the cat and dog classes.
- Prompt engineering: Very large neural networks, especially large language models like GPT-3, can be used for different tasks if given the right prompt. It can then be used for chatbots, text summarization, translation, creative inputs, …
12.4 Strengths
- Deep learning works especially well with images, text, and other hierarchical data structures. For these data, deep learning is unchallenged by the other mindsets.
- Deep neural networks do feature learning which can be leveraged for all kinds of models and eliminates the need for hand-crafted features.
- Deep learning is modular and networks can be customized for any modeling task. The only other mindset that comes close in these Lego-like modularity is Bayesian statistics.
- Neural networks are usually gradient-based. This means that you can optimize a neural network for any differentiable loss. For algorithms such as random forests, the optimized loss is often fixed and slightly mismatches the targeted loss function.
- There is a large ecosystem of software optimized for neural networks.
12.5 Limitations
- While neural networks win out on image and text data, they lose out on tabular data. For tabular data, tree-based methods such as tree-boosting and random forests dominate the field (Grinsztajn et al. 2022). If you are totally sold on deep learning, you might have an unnecessarily hard time with tabular data.
- Deep neural networks can be difficult and slow to train. Probably you need GPUs for training as well.
- Neural networks can be vulnerable to adversarial attacks. (Biggio and Roli 2018)
- Deep learning is crowded. This is a problem for researchers as it’s likely that another researcher already works on the same idea.
- Deep learning is data hungry. While statistical modeling is suitable made for small data sets, neural networks need many data points to learn anything meaningful.
References
In the early days often called artificial neural networks. Still artificial now, but, who wants to write such long words?↩︎