Chapter 11 Reinforcement Learning – Optimize Actions
- The model is an agent that interacts with an environment.
- Reinforcement learning is used in robotics, games, complex systems, and simulations among others.
- Together with supervised and unsupervised learning, reinforcement learning is a machine learning mindset.
Two machine learners attend a dinner with a huge buffet. Dumplings are in high demand, but unavailable most of the time. The supervised learner tries to predict when the waiters refill the dumplings. The reinforcement learner leaves and returns with a plate full of dumplings. “How did you get these dumplings?” asks the supervised learner. “First I tried my luck at the buffet, but of course the dumplings were gone,” explains the reinforcement learner. “Then I thought about my options and decided to talk to a waiter. That decision was rewarded with dumplings!” The supervised learner was stunned, as interacting with the environment never seemed to be an option.
Chess, Go, StarCraft II, Minecraft, Atari games, … Many people enjoy playing these games. But they have a superhuman competition: computers.
All these games require long-term planning and difficult decisions. Go has more possible board positions (\(10^{127}\)) than there are atoms in the universe (about \(10^{78}\) to \(10^{82}\)). StarCraft II is a complex real-time strategy game that requires planning, resource management and military tactics. Playing these games at superhuman levels was made possible by machine learning. Not through supervised or unsupervised learning, but through reinforcement learning: a modeling mindset that controls an agent acting in an environment.
This agent doesn’t sell houses, it doesn’t fight Neo, and it doesn’t investigate crimes. Reinforcement learning agents play Go(Silver et al. 2016), plan routes, control cooling units(Li et al. 2019), move robotic arms (Gu et al. 2017), steer self-driving cars(Kiran et al. 2021) or guide image segmentation(Wang et al. 2018). An agent in reinforcement learning is an entity that interacts with an environment with the goal of maximizing rewards. This environment can be a video game, a city map, a cooling system, an assembly line in a factory, … There are all kinds of environment: they may be stochastic or deterministic, partially or fully observable, … The agent observes (parts of) the environment, but also acts in it, thereby changing it. But how does the agent choose it’s actions? The agent is “motivated” by rewards: Defeating the other players in StarCraft, setting the right temperature in the building, collecting coins in Super Mario. The “brain” of the agent is the policy. The policy decides what the agent should do next depending on the situation.
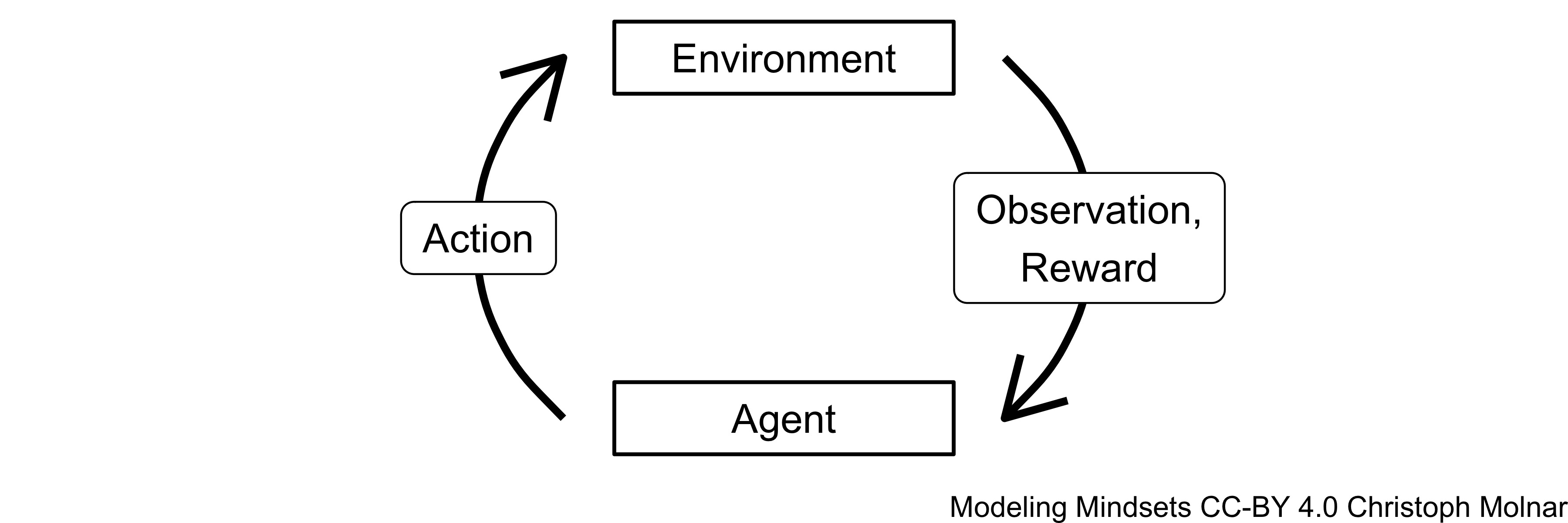
FIGURE 11.1: An agent observes the environment and chooses an action. The action might influence the environment and produce a reward.
11.1 A Dynamic Mindset
Reinforcement learning is dynamic. When using reinforcement learning to solve a task, the task is viewed as an interaction between a computer (program) and another system or environment. In comparison, the other mindsets are stationary. They work with static snapshots of the world. Interaction between computer and environment isn’t part of all the other modeling mindsets such as supervised learning or Bayesianism. In most modeling mindsets, data are usually collected first and then the model is built. In reinforcement learning, the data are generated by the agent’s interaction with the environment.11 The agent chooses which states of the environment to explore and in turn which data to generate. The computer runs its own experiments and learns from them. The agent goes through a cycle of observing the environment (which might include a reward) and choosing the next action which may influence the environment.
Think about pricing a product. A high price can mean more revenue per sale, but fewer customers. A low price can mean more customers, but less revenue per sale. The seller wants to find the optimal price that balances demand and revenue per sale. What about using supervised learning? The modeler can use historical sales data to train a model to predict the number of sales based on price and other factors (day of the week, promotions, …). This approach might be suboptimal, because it’s likely that the price fluctuations did not come through experiments, but other factors such as bonus programs and other dynamic price adaptions. Perhaps the optimal price is higher than any historical price. But supervised learning can only learn from observed data; it can’t explore new options.
Reinforcement learning can deal with this dynamic pricing situation. A change in price changes the “environment”, which in this case is a tad abstract as it consists of sales and inventory. Reinforcement learning is a way to conduct experiments with the price. It can handle the trade-off between exploring new prices and exploiting already learned pricing strategies. This makes reinforcement learning a much more holistic approach that connects interactions.
Reinforcement learning is a typical machine learning mindset. The modeler doesn’t care too much how the agent policy is implemented – the most important is that it works. Or, as Ovid said, “Exitus acta probat”, the result justifies the deed. The performance of the agent can be measured very directly by the rewards. Just average the rewards over several episodes (an episode is one game, or a simulation round) and compare these across models. A reward is an external signal and doesn’t rely on model assumptions (as many evaluation methods in statistics do). But what is a reward anyway and how does it differ from a ground truth label in supervised learning?
11.1.1 Targeting Value Instead Of Sparse and Delayed Rewards
Relaxing is easy, but exercising is hard. But why? There are immediate negative rewards associated with exercise: It’s tiring, you have to shower afterwards, you have to fit it into your daily routine, … There are also huge positive rewards, such as getting fit and strong, reducing the risk of heart attacks, and prolonging life. These positive rewards occur with a delay of weeks, years or even decades.
Reinforcement learning also deal with delayed rewards, that in addition may be sparse. For example, in Tic-tac-toe, there is only a single reward at the end of the game (win or lose). Most actions are without immediate reward and therefore without feedback. In Tic-tac-toe, if the agent loses after 4 moves, how is it supposed to know which moves were the bad ones?
One solution is to assign a value to each state. If there are only a few possible states, as in Tic-tac-toe, a table fully describes all possible states and their values. If states are continuous or the state space is too large, a function can express the value based on the state. The value function accepts a state as input, or possibly a combination of state and action. The output is the respective value.
But what is a value? Simply put, the value tells how good it is for the agent to be in that state. The value is the expected reward for a state or state-action pair. You can think of value as the reward being spread back in time, like jam on a loaf of bread. If you exercise today, it’s because you know the value of exercising. You imagine the future reward for your actions today and value the current state accordingly. Or maybe you don’t think about the value at all because working out has become a habit for you. It has become your policy.
Rewards are provided by the environment, but the values are not. The values or the value function can only be estimated. There are several ways to learn the value function. One way is to turn it into a supervised learning task! The Go algorithm Alpha Zero, for example, did exactly that. Through self-play, Alpha Zero collected a dataset of state-reward pairs. Researchers trained a neural network on this dataset to predict win (+1) or loss (-1) as a function of the game state. Another approach to learning the value function is Monte Carlo estimation: Start from random initial states, follow the current policy of the agent, and accumulate the rewards. Then average the rewards for each state. Monte Carlo estimation works only for environments with few states.
FIGURE 11.2: Trajectory of a reinforcement learning agent through the state space, with a reward at the end.
Defining the reward can be surprisingly tricky. An agent can behave like an evil genie who takes wishes (aka rewards) quite literally.[^failed-rewards] A good example is CoastRunners, a boat racing game. The agent controls a boat with the goal to win a boat race, but the score (aka reward) was increased by collecting objects on the race course. The agent learned not to finish the race. Instead, it learned to go around in circles and collect the same reappearing objects over and over again. The greedy agent scored on average 20% more points than humans.
11.2 What to Learn
For me, this was the most confusing part to getting started with reinforcement learning: What function(s) are actually learning in reinforcement learning? In supervised learning, it’s clear: the model is a function that maps the features to the label. But there is more than one function to (possibly) learn in reinforcement learning:
- Learn a complete model of the environment. The agent can query such a model to simulate the best action at each time.
- Learn the state value function. If an agent has access to a value function, it can choose actions that maximize the value.
- Learn the action-value function, which takes as input not just the state, but state and action.
- Learn the policy of the agent directly.
These approaches are not mutually exclusive, but can be combined. Oh, and also, there are many different ways how to learn these functions. And that depends on the dimensionality of the environment and the action space. For example, Tic-tac-toe and Go are pretty similar games. I imagine all the Go players reading this book will object, but hear me out. Two players face off in a fierce turn-based strategy game. The battlefield is a rectangular board and each player places markers on the grid. The winner is determined by the constellations of the markers.
Despite some similarities, the games differ in their difficulty for both humans and reinforcement learning. Tic-tac-toe is often used as an example in reinforcement learning entry classes and counts as “solved”. In contrast, Go has long been dominated by humans. The first super-human Go agent beat the Go champion Lee Sedol in 2016, which was a big media spectacle and an research/engineering feat. The deciding differences between Tic-tac-toe and Go are the size of action space and state space.
In Tic-tac-toe, there are at most 9 possible actions and on the order of \(10^3\) possible action-state pairs. The agent can learn to play Tic-tac-toe by using Q-learning, a model-free reinforcement learning approach to learn the value of an action in a given state. Q-learning basically enumerates the state-action pairs and iteratively updates the values as more and more games are played. In Go, there are \(\sim 10^{170}\) possible states. Approaches that enumerate states are futile. To work with these high-dimensional state and action spaces, neural networks work great (more on this later).
Would it be possible to use supervised learning instead? At first glance, rewards seem similar to ground truth in supervised learning. Especially with access to a value function, the policy could be learned with supervised learning, right? Not really. Supervised learning alone is unsuitable for sequential decision making that requires balancing exploration and exploitation. Imagine modeling a game like Go with a supervised learning mindset: The model would predict the next move based on the current positions on the playing field. The model could be trained with recordings of (human) games. At best, this supervised approach would mimic human players. But it could never explore novel strategies. Compared to reinforcement learning, supervised learning seems short-sighted and narrow-minded. Supervised learning only considers parts of the problem without connecting actions. Reinforcement learning is a more holistic approach that sequentially connects interactions.
11.3 Deep Reinforcement Learning
The connection between deep learning and reinforcement learning is special, so let’s go deeper here (pun intended). In short: it’s a fantastic fusion of mindsets. Reinforcement learning alone struggles with high-dimensional inputs and large state spaces. Go, for example, was too complex for reinforcement learning to solve. Other environments where the states are images or videos also difficult to model. Unless you throw deep learning into the mix.
Deep reinforcement learning has gotten many people excited about AI in general. Reinforcement learning is made “deep” by replacing some functions with deep neural networks. For example, the value function or the policy function. Using deep neural networks allows for more complex inputs such as images and to focus on end-to-end solutions where the input is the raw state of the game. A successful example of deep reinforcement learning is Alpha Zero which plays Go on a superhuman level. Alpha Zero relies on two deep neural networks: a value network and a policy network. A dataset is created from the algorithm playing against itself. This dataset stores all the states of the board and the final outcome (win or loss) for each game. The value network is trained on this self-play data to predict the outcome of the game (between -1 and +1) from the Go board. The policy network outputs action probabilities based on the Go board (the state). But the agent doesn’t automatically follow the most likely action. Instead, the policy network works in tandem with a Monte Carlo tree search algorithm. The Monte Carlo tree search connects the policy with the value of the board and simulates possible next moves. Training of the policy network is also interwoven with the Monte Carlo tree search.
11.4 Strengths
- Reinforcement learning allows to model the world in a dynamic way.
- It’s a great approach for planning, playing games, controlling robots and larger systems.
- Actions of the agent change the environment. In other mindsets, the model is a mere “observer”, which often is a false simplification.
- Reinforcement learning is proactive. It involves learning by doing, balancing exploration and exploitation, and creating experiments on the fly.
11.5 Limitations
- Reinforcement learning requires an agent. Many modeling tasks don’t translated into agent-environment scenarios.
- Often, reinforcement learning, especially deep reinforcement learning, is the wrong approach to a problem.
- Reinforcement learning models can be difficult to train and reproduce:
- Learning requires many episodes because reinforcement learning is sample inefficient.
- Designing the right reward function can be tricky.12
- Training can be unstable and can get stuck in local optima.
- Reinforcement learning models are usually trained in simulated environments. It’s difficult to transfer the models to the physical world.
- Model-free or model-based? Learn the policy? Or the value function? Or the action-value function? There are many modeling choices and this can be overwhelming.
References
Data may be collected beforehand. For example, the Alpha Go algorithm was pre-trained by Go moves from human players (in a supervised learning fashion). (Chen et al. 2018)↩︎
The paper “The surprising creativity of digital evolution” is one of my all-time favorite papers(Lehman et al. 2020). It deals with evolutionary algorithms, but it also has more general lessons about how difficult it is to design an optimization goal.↩︎