30 Adversarial Examples
An adversarial example is an instance with small, intentional feature perturbations that cause a machine learning model to make a false prediction. I recommend reading the chapter about Counterfactual Explanations first, as the concepts are very similar. Adversarial examples are counterfactual examples with the aim to deceive the model, not interpret it.
Why are we interested in adversarial examples? Are they not just curious by-products of machine learning models without practical relevance? The answer is a clear “no”. Adversarial examples make machine learning models vulnerable to attacks, as in the following scenarios.
A self-driving car crashes into another car because it ignores a stop sign. Someone had placed a picture over the sign, which looks like a stop sign with a little dirt for humans, but was designed to look like a parking prohibition sign for the sign recognition software of the car.
A spam detector fails to classify an email as spam. The spam mail has been designed to resemble a normal email, but with the intention of cheating the recipient.
A machine-learning powered scanner scans suitcases for weapons at the airport. A knife was developed to avoid detection by making the system think it is an umbrella.
Let’s take a look at some ways to create adversarial examples.
Methods and examples
There are many techniques to create adversarial examples. Most approaches suggest minimizing the distance between the adversarial example and the instance to be manipulated, while shifting the prediction to the desired (adversarial) outcome. Some methods require access to the gradients of the model, which of course only works with gradient-based models such as neural networks, while other methods only require access to the prediction function, which makes these methods model-agnostic. The methods in this section focus on image classifiers with deep neural networks, as a lot of research is done in this area and the visualization of adversarial images is very educational. Adversarial examples for images are images with intentionally perturbed pixels with the aim to deceive the model during application time. The examples impressively demonstrate how easily deep neural networks for object recognition can be deceived by images that appear harmless to humans. If you have not yet seen these examples, you might be surprised because the changes in predictions are incomprehensible for a human observer. Adversarial examples are like optical illusions, but for machines.
Something is Wrong With My Dog
Szegedy et al. (2014) used a gradient-based optimization approach in their work “Intriguing Properties of Neural Networks” to find adversarial examples for deep neural networks. One result can be seen in Figure 30.1.

These adversarial examples were generated by minimizing the following function with respect to \(\mathbf{r}\):
\[\text{loss}(\hat{f}(\mathbf{x}+\mathbf{r}), l) + c \cdot |\mathbf{r}|\]
In this formula, \(\mathbf{x}\) is an image (represented as a vector of pixels), \(\mathbf{r}\) is the change to the pixels to create an adversarial image (\(\mathbf{x} + \mathbf{r}\) produces a new image), \(l\) is the desired outcome class, and the parameter \(c\) is used to balance the distance between images and the distance between predictions. The first term is the distance between the predicted outcome of the adversarial example and the desired class \(l\); the second term measures the distance between the adversarial example and the original image. This formulation is almost identical to the loss function to generate counterfactual explanations. There are additional constraints for \(\mathbf{r}\) so that the pixel values remain between 0 and 1. The authors suggest solving this optimization problem with a box-constrained L-BFGS, an optimization algorithm that works with gradients.
Disturbed panda: Fast gradient sign method
Goodfellow, Shlens, and Szegedy (2015) invented the fast gradient sign method for generating adversarial images. The gradient sign method uses the gradient of the underlying model to find adversarial examples. The original image \(\mathbf{x}\) is manipulated by adding or subtracting a small error \(\epsilon\) to each pixel. Whether we add or subtract \(\epsilon\) depends on whether the sign of the gradient for a pixel is positive or negative. Adding errors in the direction of the gradient means that the image is intentionally altered so that the model classification fails.
The following formula describes the core of the fast gradient sign method:
\[\mathbf{x}^\prime = \mathbf{x} + \epsilon \cdot \text{sign}\left(\nabla_{\mathbf{x}} J(\boldsymbol{\theta}, \mathbf{x}, y)\right)\]
where \(\nabla_{\mathbf{x}} J\) is the gradient of the model’s loss function with respect to the original input pixel vector \(\mathbf{x}\), \(y\) is the true label for \(\mathbf{x}\), and \(\boldsymbol{\theta}\) is the model parameter vector. From the gradient vector (which is as long as the vector of the input pixels), we only need the sign: The sign of the gradient is positive (+1) if an increase in pixel intensity increases the loss (the error the model makes) and negative (-1) if a decrease in pixel intensity increases the loss. This vulnerability occurs when a neural network treats a relationship between an input pixel intensity and the class score linearly. In particular, neural network architectures that favor linearity, such as LSTMs, maxout networks, networks with ReLU activation units, or other linear machine learning algorithms such as logistic regression, are vulnerable to the gradient sign method. The attack is carried out by extrapolation. The linearity between the input pixel intensity and the class scores leads to vulnerability to outliers, i.e., the model can be deceived by moving pixel values into areas outside the data distribution. I expected these adversarial examples to be quite specific to a given neural network architecture. But it turns out that you can reuse adversarial examples to deceive networks with a different architecture trained on the same task.
Goodfellow, Shlens, and Szegedy (2015) suggested adding adversarial examples to the training data to learn robust models.
A jellyfish … No, wait. A bathtub: 1-pixel attacks
The approach presented by Goodfellow and colleagues (2014) requires many pixels to be changed, if only by a little. But what if you can only change a single pixel? Would you be able to deceive a machine learning model? Su, Vargas, and Sakurai (2019) showed that it is actually possible to deceive image classifiers by changing a single pixel, as illustrated in Figure 30.2.
Similar to counterfactuals, the 1-pixel attack looks for a modified example \(\mathbf{x}^\prime\) that comes close to the original image \(\mathbf{x}\), but changes the prediction to an adversarial outcome. However, the definition of closeness differs: Only a single pixel may change. The 1-pixel attack uses differential evolution to find out which pixel is to be changed and how. Differential evolution is loosely inspired by the biological evolution of species. A population of individuals called candidate solutions recombines generation by generation until a solution is found. Each candidate solution encodes a pixel modification and is represented by a vector of five elements: the \(x\)- and \(y\)-coordinates and the red, green, and blue (RGB) values. The search starts with, for example, 400 candidate solutions (= pixel modification suggestions) and creates a new generation of candidate solutions (children) from the parent generation using the following formula:
\[\mathbf{x}_{g+1}^{(i)} = \mathbf{x}_g^{(r1)} + F \cdot (\mathbf{x}_g^{(r2)}- \mathbf{x}_g^{(r3)})\]
where each \(x^{(i)}\) is an element of a candidate solution (either \(x\)-coordinate, \(y\)-coordinate, red, green, or blue), \(g\) is the current generation, \(F\) is a scaling parameter (set to 0.5), and \(r1\), \(r2\), and \(r3\) are different random numbers. Each new child candidate solution is in turn a pixel with the five attributes for location and color, and each of those attributes is a mixture of three random parent pixels.
The creation of children is stopped if one of the candidate solutions is an adversarial example, meaning it is classified as an incorrect class, or if the maximum number of iterations specified by the user is reached.
Everything is a toaster: Adversarial patch
One of my favorite methods brings adversarial examples into physical reality. Brown et al. (2018) designed a printable label that can be stuck next to objects to make them look like toasters for an image classifier, see Figure 30.3. Brilliant work!

This method differs from the methods presented so far for adversarial examples since the restriction that the adversarial image must be very close to the original image is removed. Instead, the method completely replaces a part of the image with a patch that can take on any shape. The image of the patch is optimized over different background images, with different positions of the patch on the images, sometimes moved, sometimes larger or smaller, and rotated, so that the patch works in many situations. In the end, this optimized image can be printed and used to deceive image classifiers in the wild.
Never bring a 3D-printed turtle to a gunfight – even if your computer thinks it is a good idea: Robust adversarial examples
The next method is literally adding another dimension to the toaster: Athalye et al. (2018) 3D-printed a turtle that was designed to look like a rifle to a deep neural network from almost all possible angles, as illustrated in Figure 30.4. Yeah, you read that right. A physical object that looks like a turtle to humans looks like a rifle to the computer!
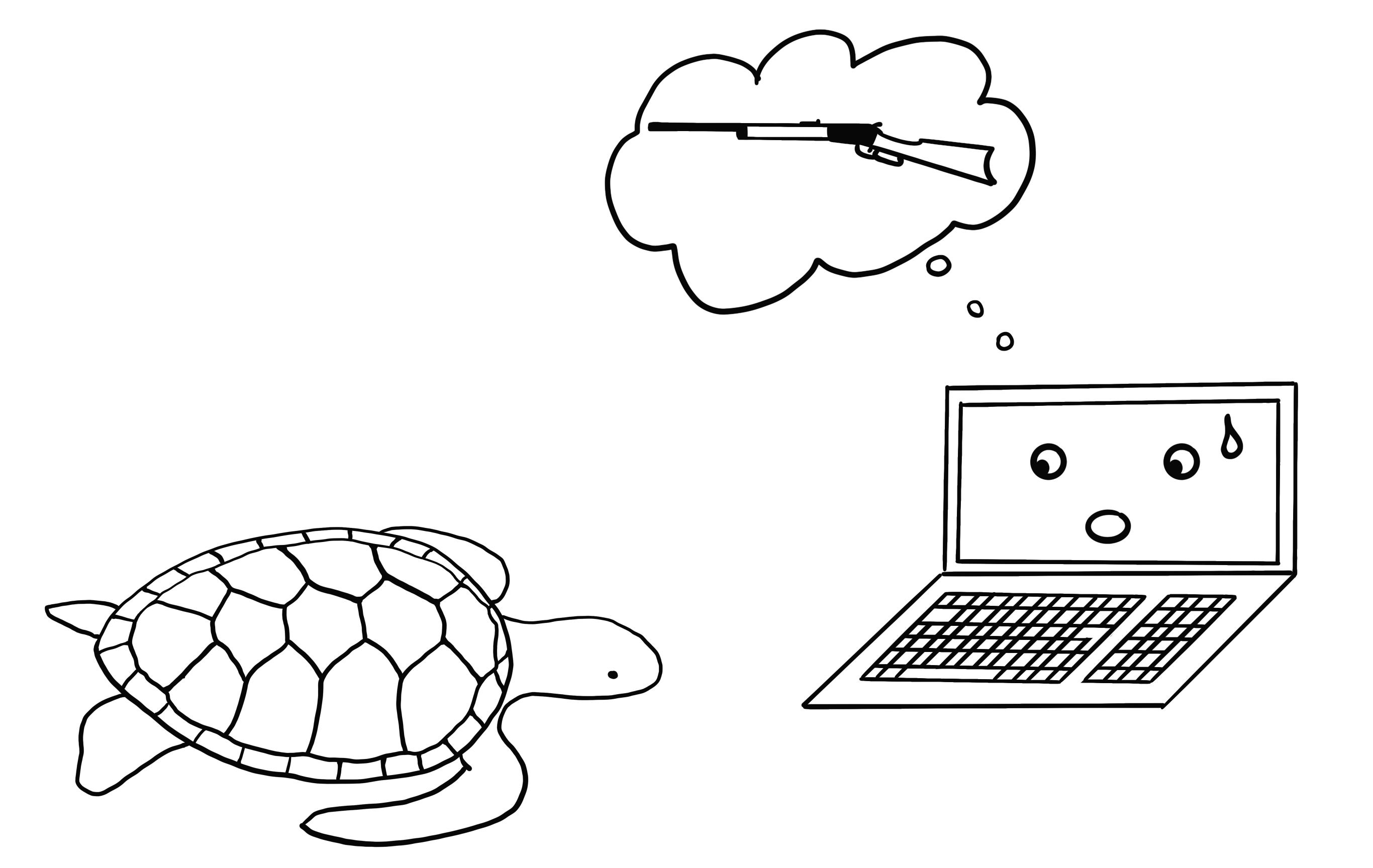
The authors have found a way to create an adversarial example in 3D for a 2D classifier that is adversarial over transformations, such as all possibilities to rotate the turtle, zoom in, and so on. Other approaches, such as the fast gradient method, no longer work when the image is rotated or the viewing angle changes. Athalye et al. (2017) propose the Expectation Over Transformation (EOT) algorithm, which is a method for generating adversarial examples that even work when the image is transformed. The main idea behind EOT is to optimize adversarial examples across many possible transformations. Instead of minimizing the distance between the adversarial example and the original image, EOT keeps the expected distance between the two below a certain threshold, given a selected distribution of possible transformations. The expected distance under transformation can be written as:
\[\mathbb{E}_{t \sim T}[d(t(\mathbf{x}^\prime), t(\mathbf{x}))]\]
where \(\mathbf{x}\) is the original image, \(t(\mathbf{x})\) the transformed image (e.g., rotated), \(\mathbf{x}^\prime\) the adversarial example, and \(t(\mathbf{x}^\prime)\) its transformed version. Apart from working with a distribution of transformations, the EOT method follows the familiar pattern of framing the search for adversarial examples as an optimization problem. We try to find an adversarial example \(\mathbf{x}^\prime\) that maximizes the probability for the selected class \(y_t\) (e.g., “rifle”) across the distribution of possible transformations \(T\):
\[\arg\max_{\mathbf{x}^\prime} \mathbb{E}_{t \sim T}[\log \mathbb{P}(y_t | t(\mathbf{x}^\prime))]\]
With the constraint that the expected distance over all possible transformations between adversarial example \(\mathbf{x}^\prime\) and original image \(\mathbf{x}\) remains below a certain threshold:
\[\mathbb{E}_{t \sim T}[d(t(\mathbf{x}^\prime), t(\mathbf{x}))] < \epsilon \quad \text{and} \quad \mathbf{x} \in [0,1]^d\]
I think we should be concerned about the possibilities this method enables. The other methods are based on the manipulation of digital images. However, these 3D-printed, robust adversarial examples can be inserted into any real scene and deceive a computer to wrongly classify an object. Let’s turn it around: What if someone creates a rifle that looks like a turtle?
The blindfolded adversary: Black box attack
Imagine the following scenario: I give you access to my great image classifier via Web API. You can get predictions from the model, but you do not have access to the model parameters. From the convenience of your couch, you can send data, and my service answers with the corresponding classifications. Most adversarial attacks are not designed to work in this scenario because they require access to the gradient of the underlying deep neural network to find adversarial examples. Papernot et al. (2017) showed that it is possible to create adversarial examples without internal model information and without access to the training data. This type of (almost) zero-knowledge attack is called a black box attack.
How it works:
- Start with a few images that come from the same domain as the training data, e.g., if the classifier to be attacked is a digit classifier, use images of digits. The knowledge of the domain is required, but not the access to the training data.
- Get predictions for the current set of images from the black box.
- Train a surrogate model on the current set of images (for example, a neural network).
- Create a new set of synthetic images using a heuristic that examines for the current set of images in which direction to manipulate the pixels to make the model output have more variance.
- Repeat steps 2 to 4 for a predefined number of epochs.
- Create adversarial examples for the surrogate model using the fast gradient method (or similar).
- Attack the original model with adversarial examples.
The aim of the surrogate model is to approximate the decision boundaries of the black box model, but not necessarily to achieve the same accuracy.
The authors tested this approach by attacking image classifiers trained on various cloud machine learning services. These services train image classifiers on user-uploaded images and labels. The software trains the model automatically – sometimes with an algorithm unknown to the user – and deploys it. The classifier then gives predictions for uploaded images, but the model itself cannot be inspected or downloaded. The authors were able to find adversarial examples for various providers, with up to 84% of the adversarial examples being misclassified.
The method even works if the black box model to be deceived is not a neural network. This includes machine learning models without gradients, such as decision trees.
The cybersecurity perspective
Machine learning deals with known unknowns: predicting unknown data points from a known distribution. The defense against attacks deals with unknown unknowns: robustly predicting unknown data points from an unknown distribution of adversarial inputs. As machine learning is integrated into more and more systems, such as autonomous vehicles or medical devices, they are also becoming entry points for attacks. Even if the predictions of a machine learning model on a test dataset are 100% correct, adversarial examples can be found to deceive the model. The defense of machine learning models against cyber attacks is a new part of the field of cybersecurity.
Biggio and Roli (2018) give a nice review of ten years of research on adversarial machine learning, on which this section is based. Cybersecurity is an arms race in which attackers and defenders outwit each other time and again.
There are three golden rules in cybersecurity: 1) know your adversary, 2) be proactive, and 3) protect yourself.
Different applications have different adversaries. People who try to defraud other people via email for their money are adversary agents of users and providers of email services. The providers want to protect their users so that they can continue using their mail program; the attackers want to get people to give them money. Knowing your adversaries means knowing their goals. Assuming you do not know that these spammers exist and the only abuse of the email service is sending pirated copies of music, then the defense would be different (e.g., scanning the attachments for copyrighted material instead of analyzing the text for spam indicators).
Being proactive means actively testing and identifying weak points of the system. You’re proactive when you actively try to deceive the model with adversarial examples and then defend against them. Using interpretation methods to understand which features are important and how features affect the prediction is also a proactive step in understanding the weaknesses of a machine learning model. As the data scientist, do you trust your model in this dangerous world without ever having looked beyond the predictive power on a test dataset? Have you analyzed how the model behaves in different scenarios, identified the most important inputs, and checked the prediction explanations for some examples? Have you tried to find adversarial inputs? The interpretability of machine learning models plays a major role in cybersecurity. Being reactive, the opposite of proactive, means waiting until the system has been attacked and only then understanding the problem and installing some defensive measures.
How can we protect our machine learning systems against adversarial examples? A proactive approach is the iterative retraining of the classifier with adversarial examples, also called adversarial training. Other approaches are based on game theory, such as learning invariant transformations of the features or robust optimization (regularization). Another proposed method is to use multiple classifiers instead of just one and have them vote on the prediction (ensemble), but that has no guarantee to work, since they could all suffer from similar adversarial examples. Another approach that does not work well either is gradient masking, which can be achieved by constructing a model without useful gradients by using a nearest neighbor classifier instead of the original model.
We can distinguish types of attacks by how much an attacker knows about the system. The attackers may have perfect knowledge (white box attack), meaning they know everything about the model like the type of model, the parameters, and the training data; the attackers may have partial knowledge (gray box attack), meaning they might only know the feature representation and the type of model that was used, but have no access to the training data or the parameters; the attackers may have zero knowledge (black box attack), meaning they can only query the model in a black box manner but have no access to the training data or information about the model parameters. Depending on the level of information, the attackers can use different techniques to attack the model. As we have seen in the examples, even in the black box case adversarial examples can be created, so that hiding information about data and the model is not sufficient to protect against attacks.
Given the nature of the cat-and-mouse game between attackers and defenders, we will see a lot of development and innovation in this area. Just think of the many different types of spam emails that are constantly evolving. New methods of attacks against machine learning models are invented, and new defensive measures are proposed against these new attacks. More powerful attacks are developed to evade the latest defenses and so on, ad infinitum. With this chapter, I hope to sensitize you to the problem of adversarial examples and that only by proactively studying the machine learning models are we able to discover and remedy weaknesses.