temp_copy).
Leave One Feature Out (LOFO) Importance measures a feature’s importance by retraining the model without the feature and comparing the predictive performances.1
The intuition behind LOFO Importance: If dropping a feature makes the predictive performance worse, then it was an important feature. If dropping the feature keeps performance unchanged, it was not important. LOFO importance may even be negative when removing the feature improves the model performance. Since the algorithm gets to train a new model, the drop in performance is conditional on the other features that remain in the model, as we will see in the examples.
To get the LOCO importance for all \(p\) features, we have to retrain the model \(p\) times, each time with a different feature removed from the training data, and measure the resulting model’s performance on test data. This makes LOFO a quite simple algorithm. Let’s formalize the algorithm:
Input: Trained model \(\hat{f}\), training data \((\mathbf{X}_{\text{train}}, \mathbf{y}_{\text{train}})\), test data \((\mathbf{X}_{\text{test}}, \mathbf{y}_{\text{test}})\), and error measure \(L\).
Procedure:
Measure the original model error:
\[
e_{\text{orig}} = \frac{1}{n_{\text{test}}} \sum_{i=1}^{n_{\text{test}}} L\big(y_{\text{test}}^{(i)}, \hat{f}(\mathbf{x}_{\text{test}}^{(i)})\big)
\]
For each feature \(j \in \{1, \ldots, p\}\):
Calculate LOFO importance for each feature.
Sort and visualize the features by descending importance \(LOFO_j\).
When using performance measures for \(L\) instead of error measures, where larger is better, like accuracy, make sure to multiply the difference by -1, or switch the order of the quotient. To train and retrain the model use the training data, and for measuring the performance use test data.
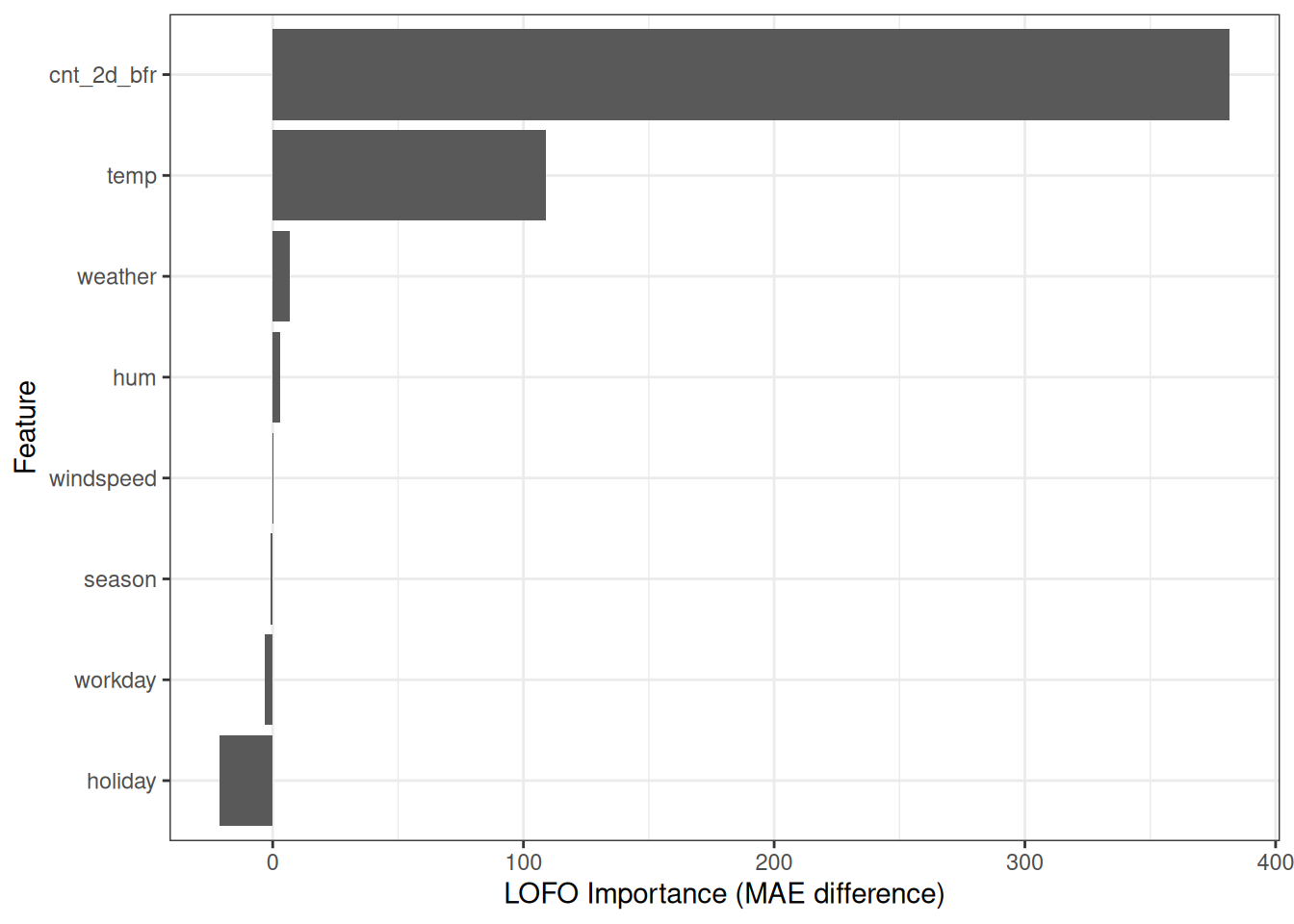
We predict bike rentals based on weather and calendar information using a random forest trained on 2/3 of the data. Figure 24.1 shows that temperature and previous number of bike rentals are the most important features according to LOFO. The holiday feature has a negative importance, which has implications for feature selection: Because of how LOFO works algorithmically, we now know that removing the holiday feature increases the model’s performance.
temp_copy).
Let’s try something. To simulate an extreme version of correlated features, I created a new bike dataset which has two temperature columns: temp and temp_copy. And, you guessed it, temp_copy has the exact same values as temp, which means 100% correlation. Again, I trained a random forest on this new dataset. Let’s see what happens to the LOFO importances.
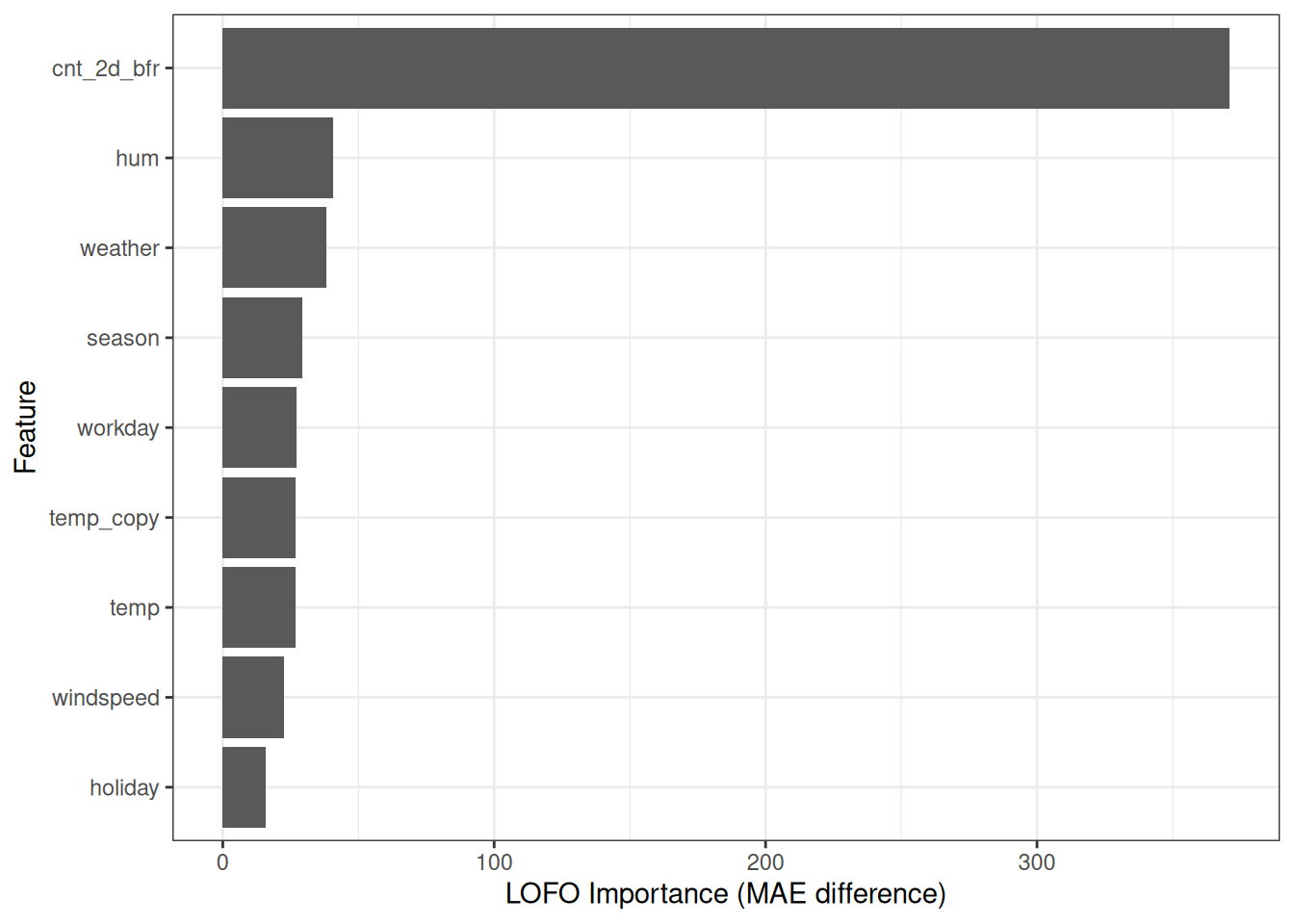
Figure 24.2 shows an interesting phenomenon: The LOFO importances of both temperature features are now almost zero.2 But if we e.g. remove temp_copy, we end up with the original model, for which we knew that temp was the most important feature. Clearly, it would be wrong to conclude that this new model doesn’t rely on temperature at all. Both temp and temp_copy get a low importance because, by the definition of LOFO importance, they are not important. When we remove the feature temp, we don’t lose any information at all. That’s because LOFO has a conditional interpretation: Given the other features, how much will removing a feature worsen the model’s predictive performance? Conclusions:
With that knowledge, let’s try LOFO for a random forest predicting penguin sex from body measurements. For this, I’ve trained a random forest on 2/3 of the data, leaving 1/3 of the data for error estimation. Figure 24.3 shows that the bill depth was the most important feature according to LOFO.
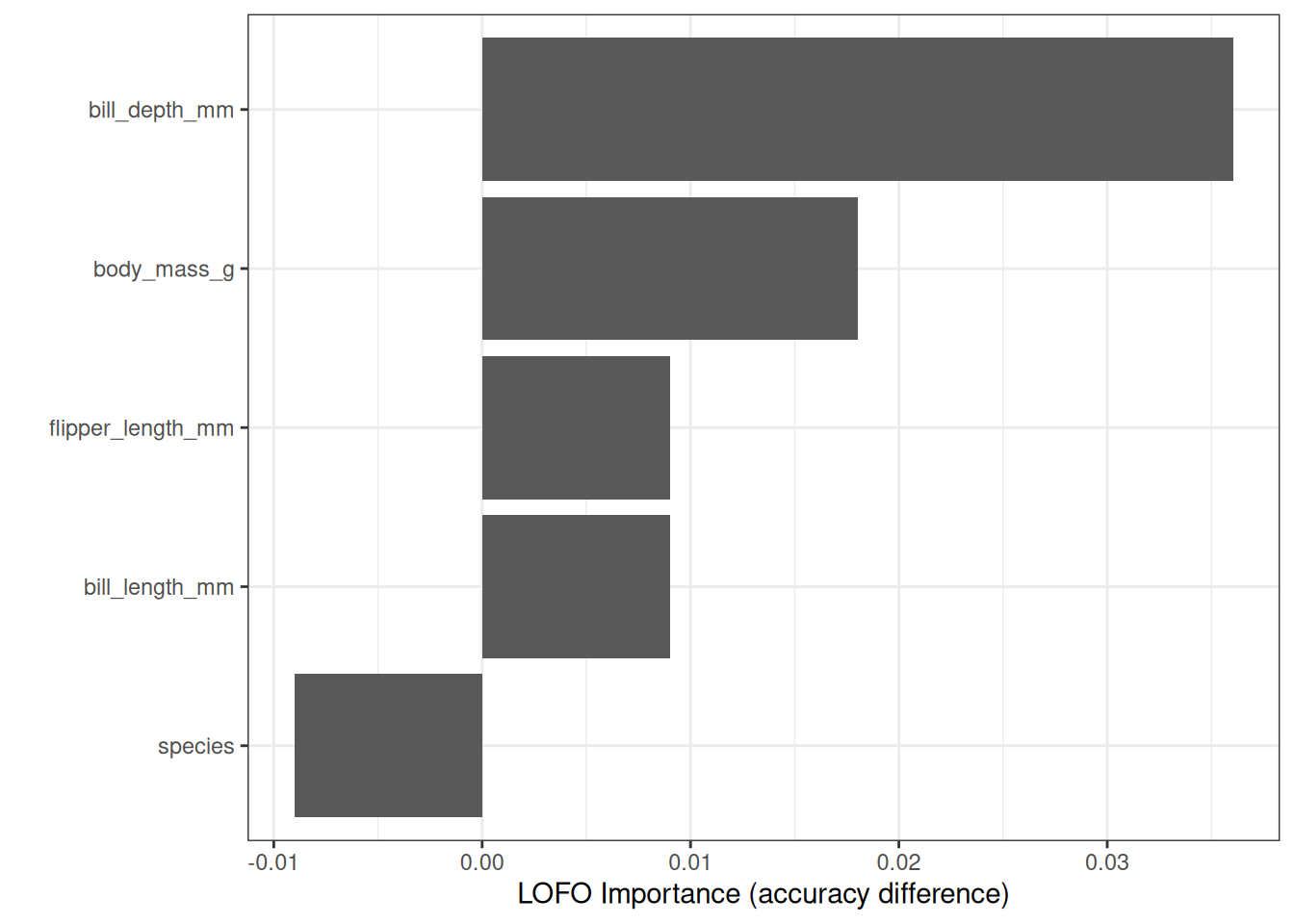
Note that because of using accuracy here, where larger is better, I multiplied the importance by minus one. LOFO also tells us that we could safely remove the features species and flipper_length. However, we would want to keep species, because the model has to be able to distinguish between the species.
LOFO differs from the other methods presented in this book, since most of the other methods don’t require retraining the model. Arguably, LOFO is a post-hoc, model-agnostic method, since it can be applied to any model and retraining the model doesn’t affect the original model that we want to interpret. However, due to retraining the model, the interpretation shifts from only interpreting that one single model to interpreting the learner and how model training reacts to changes in the features.
To me, the biggest question is: How does LOFO compare to PFI, and when should you use which importance? Let’s start with the similarities: Both PFI and LOFO are performance-based importance measures; both compute importance by “removing” the information of a feature, even when they do it differently; both work in a one-at-a-time way, at least in their simplest version. But LOFO and PFI differ in other aspects. As we already saw in the example Figure 24.2, LOFO has a conditional interpretation of importance. It’s only about a feature’s additional predictive value. This distinguishes LOFO from marginal permutation feature importance. LOFO is more similar to conditional PFI, and they both have interpretations conditional on the other features.
But since conditional PFI and LOFO work differently, they differ in their interpretations. Conditional PFI is an interpretation that only involves the model at hand. LOFO importance focuses more on the machine learning algorithm, since it involves retraining the model, and the interpretation now involves multiple models trained differently. This also means that LOFO importance is affected by how the machine learning algorithm handles datasets with one fewer column. A decision tree algorithm might produce a completely different tree. Therefore LOFO’s interpretation is both about the model at hand, but also about the machine learning algorithm and how it reacts to removing a feature.
Implementing LOFO is simple. For the examples here I did just that. You can do it yourself, you don’t actually need any package for that.
LOFO is useful for feature selection: A feature with a LOFO importance below zero can be removed to improve model performance; a feature with an importance of zero can also be safely removed without affecting the performance. However, be aware that LOFO is subject to the randomness of the training process and also depends on the data sample. Just make sure that you remove only one feature at a time based on LOFO importance results. If you want to remove two features, you have to do it sequentially, meaning compute LOFO importance, remove the unimportant feature, compute LOFO again, and remove again the least important. You can also adapt LOFO to LTFO (leave two features out) to compute shared importance. Other importance methods, like PFI or SHAP importance, don’t directly provide actionable feature selection information.
LOFO doesn’t create unrealistic data like other methods, such as marginal PFI, since LOFO removes features and doesn’t probe the model with newly sampled data.
LOFO is useful for the modeling phase due to its actionable insights for feature selection. It’s also useful when the focus is more on understanding the underlying phenomenon and less on the model itself. Note, however, that also how the specific learner reacts to removing features will influence the LOFO importance values.
LOFO makes sense when your goal of interpretation is about the phenomenon (and less about the model itself) or the learner.
LOFO is costly: If you compute LOFO importance for all features, you have to retrain the model \(p\) times. This can be costly, especially when compared to Permutation Feature Importance.
LOFO is not the best method for understanding a specific model. For example, for more of a model audit setting, LOFO is not suitable since the interpretation is based on training new models, meaning the interpretation is not only based on the model under inspection, but also on other models produced by the machine learning algorithm, so that results are to be interpreted in terms of the machine learning algorithm.
It’s also a bit unclear how to handle hyperparameter tuning. Should you train with the exact same hyperparameters, or run the hyperparameter optimization again? Keeping the hyperparameters fixed is computationally cheaper and shifts LOFO’s focus more on that model as the newly trained models are potentially more similar to it. Running hyperparameter optimization for each of the \(p\) models is costly, but makes LOFO results more informative for feature selection and insights into the relations between features and the target since you reduce uncertainty due to model errors.
Highly correlated features get low LOFO importance. This is to be expected simply by how LOFO works, but it’s a pitfall and easily forgotten when looking at the importance plots. It also means that studying the correlations of your data is a must before you can interpret LOFO importances. You can also group highly correlated features and only remove them together so your interpretation becomes more marginal than conditional.
LOFO has a Python implementation. But it’s also an algorithm you can implement yourself easily.
An alternative to LOFO is conditional PFI. It’s also possible to add a permuted version of the variable instead of dropping it, and then relearning a model. This has the advantage of comparing two models with the same number of features, but it introduces another source of uncertainty (the permutation itself is random).
The feature selection method “backward sequential feature selection” is basically LOFO + feature removal applied sequentially.
The first formal description of LOFO I’m aware of is by Lei et al. (2018). They call it Leave One Covariate Out (LOCO), and the paper is mostly about distribution-free testing.↩︎
The features temp and temp_copy have similar but not equal LOFO importances, which is due to randomness in the model training.↩︎
We need to assume here that the learner is able to compensate for the removal of a feature by relying more on the other features. But I don’t know of any machine learning algorithm that isn’t capable of that.↩︎