Appendix A — Machine Learning Terms
To avoid confusion due to ambiguity, here are some definitions of terms used in this book:
An Algorithm is a set of rules that a machine follows to achieve a particular goal (Merriam-Webster 2017). An algorithm can be considered as a recipe that defines the inputs, the output, and all the steps needed to get from the inputs to the output. Cooking recipes are algorithms where the ingredients are the inputs, the cooked food is the output, and the preparation and cooking steps are the algorithm instructions.
Machine Learning is a set of methods that allow computers to learn from data to make and improve predictions (for example, predicting cancer, weekly sales, credit default). Machine learning is a paradigm shift from “normal programming” where all instructions must be explicitly given to the computer to “indirect programming” that takes place through providing data.
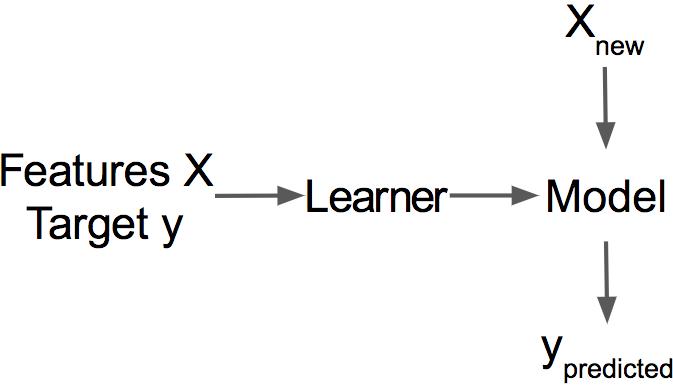
A Learner or Machine Learning Algorithm is the program used to learn a machine learning model from data. Another name is “inducer” (e.g., “tree inducer”).
A Machine Learning Model is the learned program that maps inputs to predictions. This can be a set of weights for a linear model or for a neural network. Other names for the rather unspecific word “model” are “predictor” or - depending on the task - “classifier” or “regression model”. In formulas, the trained machine learning model is called \(\hat{f}\) or \(\hat{f}(\mathbf{x})\).
A Black Box Model is a system that does not reveal its internal mechanisms. In machine learning, the term “black box” describes models that cannot be understood by looking at their parameters (e.g., a neural network). The opposite of a black box is sometimes referred to as White Box, and is called interpretable model in this book. Model-agnostic methods for interpretability treat machine learning models as black boxes, even if they are not.

Interpretable Machine Learning refers to methods and models that make the behavior and predictions of machine learning systems understandable to humans.
A Dataset is a table with the data from which the machine learns. The dataset contains the features and the target to predict. When used to induce a model, the dataset is called training data.
An Instance is a row in the dataset. Other names for ‘instance’ are: (data) point, example, observation. An instance consists of the feature values \(\mathbf{x}^{(i)}\) and, if known, the target outcome \(y^{(i)}\).
The Features are the inputs used for prediction or classification. A feature is a column in the dataset. Throughout the book, features are assumed to be interpretable, meaning it is easy to understand what they mean, like the temperature on a given day or the height of a person. The interpretability of the features is a big assumption. But if it is hard to understand the input features, it is even harder to understand what the model does. The matrix with all features is called \(\mathbf{X}\) and \(\mathbf{x}^{(i)}\) for a single instance. The vector of a single feature for all instances is \(\mathbf{x}_j\) and the value for the feature \(j\) and instance \(i\) is \(x^{(i)}_j\).
The Target is the information the machine learns to predict. In mathematical formulas, the target is usually called \(y\) or \(y^{(i)}\) for a single instance.
A Machine Learning Task is the combination of a dataset with features and a target. Depending on the type of the target, the task could be classification, regression, survival analysis, clustering, or outlier detection.
The Prediction is the machine learning model’s “guess” for the target value based on the given features. In this book, the model prediction is denoted by \(\hat{f}(\mathbf{x}^{(i)})\) or \(\hat{y}\).