| location | size | pets | value |
|---|---|---|---|
| good | small | yes | high |
| good | big | no | high |
| good | big | no | high |
| bad | medium | no | ok |
| good | medium | only cats | ok |
| good | small | only cats | ok |
| bad | medium | yes | ok |
| bad | small | yes | low |
| bad | medium | yes | low |
| bad | small | no | low |
10 Decision Rules
A decision rule is a simple IF-THEN statement consisting of a condition (also called antecedent) and a prediction. For example: IF it rains today AND if it is April (condition), THEN it will rain tomorrow (prediction). A single decision rule or a combination of several rules can be used to make predictions.
Decision rules follow a general structure: IF the conditions are met THEN make a certain prediction. Decision rules are probably the most interpretable prediction models: Their IF-THEN structure semantically resembles natural language and the way we think, provided that the condition is built from intelligible features, the length of the condition is short (small number of feature=value pairs combined with an AND) and there are not too many rules. In programming, it’s very natural to write IF-THEN rules. New in machine learning is that the decision rules are learned through an algorithm.
Imagine using an algorithm to learn decision rules for predicting the value of a house (low, ok or high). One decision rule learned by this model could be: If a house is bigger than 100 square meters and has a garden, then its value is high. More formally: IF size>100 AND garden=1 THEN value=high.
Let’s break down the decision rule:
size>100is the first condition in the IF-part.garden=1is the second condition in the IF-part.- The two conditions are connected with an ‘AND’ to create a new condition. Both must be true for the rule to apply.
- The predicted outcome (THEN-part) is
value=high.
A decision rule uses at least one feature=value statement in the condition, with no upper limit on how many more can be added with an ‘AND’. An exception is the default rule that has no explicit IF-part and that applies when no other rule applies, but more about this later.
The usefulness of a decision rule is usually summarized in two numbers: support and accuracy.
Support or coverage of a rule: The percentage of instances to which the condition of a rule applies is called the support. Take for example the rule size=big AND location=good THEN value=high for predicting house values. Suppose 100 of 1,000 houses are big and in a good location, then the support of the rule is 10%. The prediction (THEN-part) is not important for the calculation of support.
Accuracy or confidence of a rule: The accuracy of a rule is a measure of how accurate the rule is in predicting the correct class for the instances to which the condition of the rule applies. For example: Let’s say of the 100 houses, where the rule size=big AND location=good THEN value=high applies, 85 have value=high, 14 have value=ok and 1 has value=low, then the accuracy of the rule is 85%.
Usually, there is a trade-off between accuracy and support: By adding more features to the condition, we can achieve higher accuracy, but lose support.
To create a good classifier for predicting the value of a house, you might need to learn not only one rule but maybe 10 or 20. Then things can get more complicated, and you can run into one of the following problems:
- Rules can overlap: What if I want to predict the value of a house and two or more rules apply and they give me contradictory predictions?
- No rule applies: What if I want to predict the value of a house and none of the rules apply?
There are two main strategies for combining multiple rules: Decision lists (ordered) and decision sets (unordered). Both strategies imply different solutions to the problem of overlapping rules.
A decision list introduces an order to the decision rules. If the condition of the first rule is true for an instance, we use the prediction of the first rule. If not, we go to the next rule and check if it applies, and so on. Decision lists solve the problem of overlapping rules by only returning the prediction of the first rule in the list that applies.
A decision set resembles a democracy of the rules, except that some rules might have a higher voting power. In a set, the rules are either mutually exclusive, or there is a strategy for resolving conflicts, such as majority voting, which may be weighted by the individual rule accuracies or other quality measures. Interpretability suffers potentially when several rules apply.
Both decision lists and sets can suffer from the problem that no rule applies to an instance. This can be resolved by introducing a default rule. The default rule is the rule that applies when no other rule applies. The prediction of the default rule is often the most frequent class of the data points that are not covered by other rules. If a set or list of rules covers the entire feature space, we call it exhaustive. By adding a default rule, a set or list automatically becomes exhaustive.
There are many ways to learn rules from data, and this book is far from covering them all. This chapter shows you three of them. The algorithms are chosen to cover a wide range of general ideas for learning rules, so all three of them represent very different approaches.
- OneR learns rules from a single feature. OneR is characterized by its simplicity, interpretability and its use as a benchmark.
- Sequential covering is a general procedure that iteratively learns rules and removes the data points that are covered by the new rule. This procedure is used by many rule learning algorithms.
- Bayesian Rule Lists combine pre-mined frequent patterns into a decision list using Bayesian statistics. Using pre-mined patterns is a common approach used by many rule learning algorithms.
Let’s start with the simplest approach: Using the single best feature to learn rules.
Learn rules from a single feature (OneR)
The OneR algorithm (Holte 1993) is one of the simplest rule induction algorithms. From all the features, OneR selects the one that carries the most information about the outcome of interest and creates decision rules from this feature.
Despite the name OneR, which stands for “One Rule,” the algorithm generates more than one rule: It’s actually one rule per unique feature value of the selected best feature. A more fitting name would be OneFeatureRule.
The algorithm is simple and fast:
- Discretize the continuous features by choosing appropriate intervals.
- For each feature:
- Create a cross table between the feature values and the (categorical) outcome.
- For each value of the feature, create a rule which predicts the most frequent class of the instances that have this particular feature value (can be read from the cross table).
- Calculate the total error of the rules for the feature.
- Select the feature with the smallest total error.
OneR always covers all instances of the dataset, since it uses all levels of the selected feature. Missing values can be either treated as an additional feature value or be imputed beforehand.
A OneR model is a decision tree with only one split. The split is not necessarily binary as in CART, but depends on the number of unique feature values.
Use OneR as baseline
OneR makes for a great baseline to compare more complex models against.
Let’s look at an example of how the best feature is chosen by OneR. Table 10.1 shows an artificial dataset about houses with information about their value, location, size, and whether pets are allowed. We are interested in learning a simple model to predict the value of a house.
OneR constructs rules based on the cross-tables between each feature and the outcome. Table 10.2 shows the three cross tables.
| value=low | value=ok | value=high | |
|---|---|---|---|
| size=big | 0 | 0 | 2 |
| size=medium | 1 | 3 | 0 |
| size=small | 2 | 1 | 1 |
| pets=no | 1 | 1 | 2 |
| pets=only cats | 0 | 2 | 0 |
| pets=yes | 2 | 1 | 1 |
| location=bad | 3 | 2 | 0 |
| location=good | 0 | 2 | 3 |
For each feature, we go through the table row by row: Each feature value is the IF-part of a rule; the most common class for instances with this feature value is the prediction, the THEN-part of the rule. For example, the size feature with the levels small, medium, and big results in three rules. For each feature, we calculate the total error rate of the generated rules, which is the sum of the errors. The location feature has the possible values bad and good. The most frequent value for houses in bad locations is low, and when we use low as a prediction, we make two mistakes, because two houses have an ok value. The predicted value of houses in good locations is high, and again we make two mistakes, because two houses have an ok value. The error we make by using the location feature is \(\frac{4}{10}\), for the size feature it is \(\frac{3}{10}\), and for the pet feature it is \(\frac{4}{10}\). The size feature produces the rules with the lowest error and will be used for the final OneR model:
IF size=small THEN value=low
IF size=medium THEN value=ok
IF size=big THEN value=high
If not properly validated, OneR may overfit on features with many possibly levels. Imagine a dataset that contains only noise and no signal, which means that all features take on random values and have no predictive value for the target. Some features have more levels than others. The features with more levels can now more easily overfit. A feature that has a separate level for each instance from the data would perfectly predict the entire training dataset. A solution would be to split the data into training and validation sets, learn the rules on the training data, and evaluate the total error for choosing the feature on the validation set.
Use validation data
Always validate your chosen model with a separate validation set to ensure that it performs well on unseen data, even if it’s a simple “one-rule” model.
Ties are another issue, i.e. when two features result in the same total error. OneR solves ties by either taking the first feature with the lowest error or the one with the lowest p-value of a chi-squared test.
Example
Let’s try OneR with real data. We use the Palmer penguins data to test the OneR algorithm. All continuous input features were discretized into 5 quantiles. The rules created by the OneR learning algorithms are shown in Table 10.3.
| bill_depth_mm | prediction |
|---|---|
| (13.1,14.7] | female |
| (14.7,16.3] | male |
| (16.3,18] | female |
| (18,19.6] | male |
| (19.6,21.2] | male |
The bill_depth_mm feature was chosen by OneR as the best predictive feature. To get a better feel for how this one rule performs, let’s look into the cross table between the (discretized) bill_depth_mm feature and the penguin species, see Table 10.4.
| bill_depth_mm | female | male |
|---|---|---|
| [13.1,14.7) | 86.7% (13) | 13.3% (2) |
| [14.7,16.3) | 38.5% (10) | 61.5% (16) |
| [16.3,18) | 72.0% (18) | 28.0% (7) |
| [18,19.6) | 34.4% (11) | 65.6% (21) |
| [19.6,21.2) | 0% (0) | 100.0% (12) |
We can see that this feature is particularly useful for classifying penguins with deep bills. Penguins with bills with a depth of over 1.98 cm are most likely to be male. Very short bills make it likely that we are dealing with a female penguin. Caveat: This model ignores the species, or rather bundles them all together. To fix this, we could train one model per species.
OneR doesn’t inherently support regression tasks. But we can turn a regression task into a classification task by cutting the continuous outcome into intervals. We use this trick to predict the number of rented bikes with OneR by cutting the number of bikes into its four quartiles (0-25%, 25-50%, 50-75%, and 75-100%). Table 10.5 shows the selected feature after fitting the OneR model: The selected feature is the previous bike rental count.
| cnt_2d_bfr | prediction |
|---|---|
| (13.3,1.76e+03] | [22,3193] |
| (1.76e+03,3.5e+03] | [22,3193] |
| (3.5e+03,5.24e+03] | (4551,5978.5] |
| (5.24e+03,6.98e+03] | (5978.5,8714] |
| (6.98e+03,8.72e+03] | (5978.5,8714] |
Now we move from the simple OneR algorithm to a more complex procedure using rules with more complex conditions consisting of several features: Sequential Covering.
Sequential covering
Sequential covering is a general procedure that repeatedly learns a single rule to create a decision list (or set) that covers the entire dataset rule by rule. Many rule-learning algorithms are part of the sequential covering family. This chapter introduces the main recipe and uses RIPPER, a variant of the sequential covering algorithm, for the examples.
The idea is simple: First, find a good rule that applies to some of the data points. Remove all data points that are covered by the rule. A data point is covered when the conditions apply, regardless of whether the points are classified correctly or not. Repeat the rule-learning and removal of covered points with the remaining points until no more points are left, or another stop condition is met. The result is a decision list. This approach of repeated rule-learning and removal of covered data points is called “separate-and-conquer.”
Suppose we already have an algorithm that can create a single rule that covers part of the data. The sequential covering algorithm for two classes (one positive, one negative) works like this:
- Start with an empty list of rules (rlist).
- Learn a rule \(r\).
- While the list of rules is below a certain quality threshold (or positive examples are not yet covered):
- Add rule \(r\) to rlist.
- Remove all data points covered by rule \(r\).
- Learn another rule on the remaining data.
- Return the decision list.
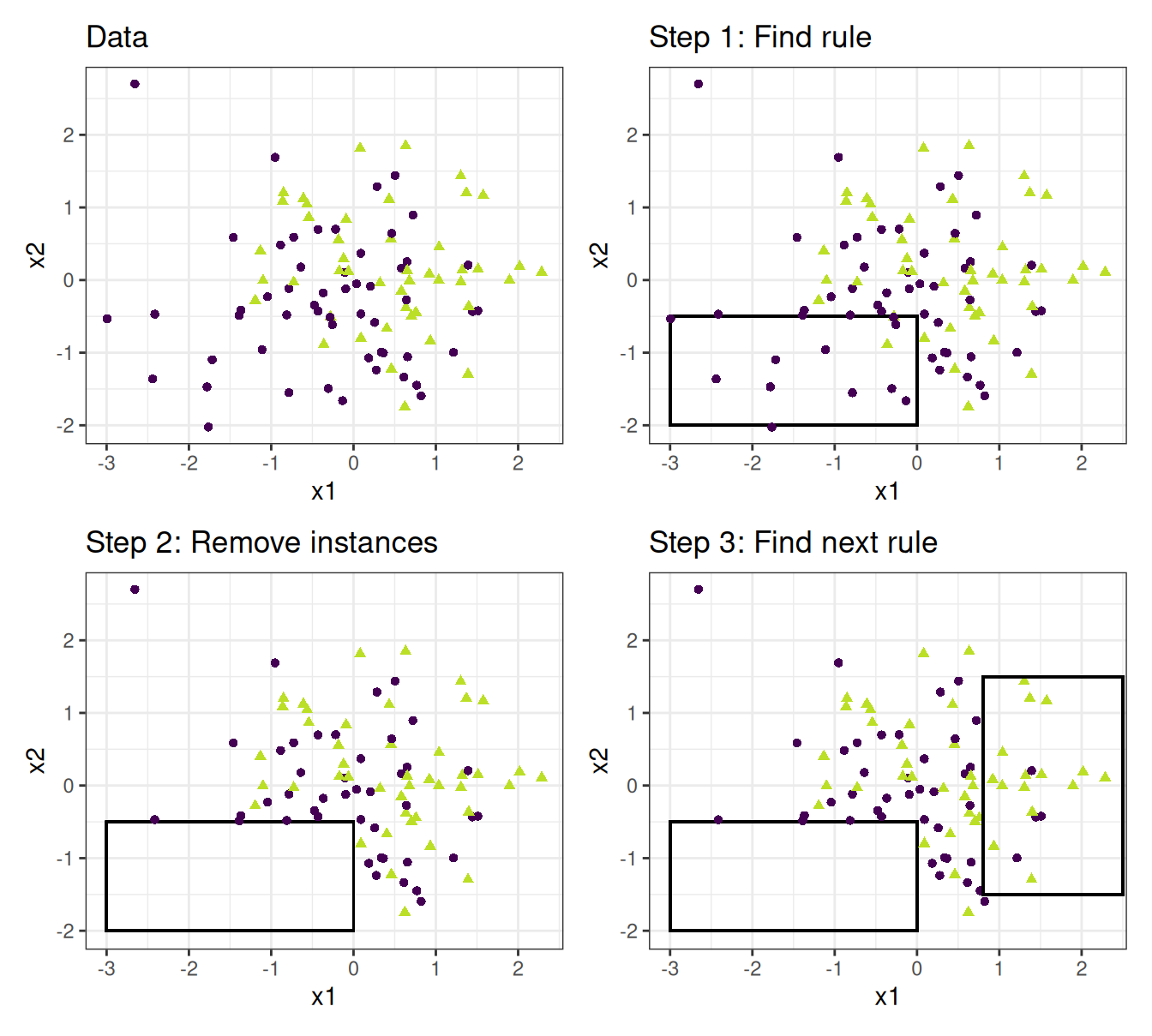
For example: We have a task and dataset for predicting the values of houses from size, location, and whether pets are allowed. We learn the first rule, which turns out to be: If size=big and location=good, then value=high. Then we remove all big houses in good locations from the dataset. With the remaining data, we learn the next rule. Maybe: If location=good, then value=ok. Note that this rule is learned on data without big houses in good locations, leaving only medium and small houses in good locations.
For multi-class settings, the approach must be modified. First, the classes are ordered by increasing prevalence. The sequential covering algorithm starts with the least common class, learns a rule for it, removes all covered instances, then moves on to the second least common class, and so on. The current class is always treated as the positive class, and all classes with a higher prevalence are combined in the negative class. The last class is the default rule. This is also referred to as one-versus-all strategy in classification.
How do we learn a single rule? The OneR algorithm wouldn’t work here since it would always cover the whole feature space. But there are many other possibilities. One possibility is to learn a single rule from a decision tree with beam search:
- Learn a decision tree (with CART or another tree learning algorithm).
- Start at the root node and recursively select the purest node (e.g., with the lowest misclassification rate).
- The majority class of the terminal node is used as the rule prediction; the path leading to that node is used as the rule condition.
Figure 10.1 illustrates the beam search in a tree:
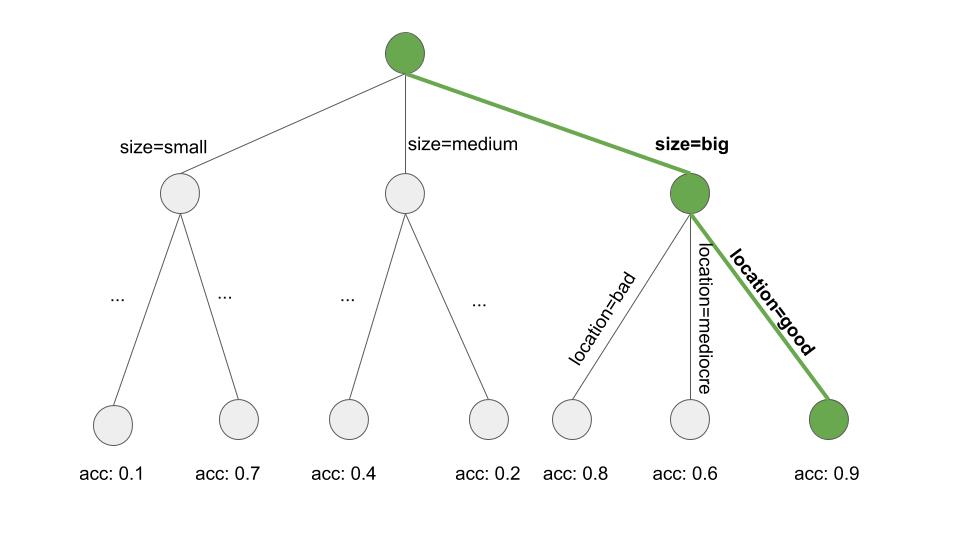
location=good and size=big, then value=high.
Learning a single rule is a search problem, where the search space is the space of all possible rules. The goal of the search is to find the best rule according to some criteria. There are many different search strategies: hill-climbing, beam search, exhaustive search, best-first search, ordered search, stochastic search, top-down search, bottom-up search, …
RIPPER (Repeated Incremental Pruning to Produce Error Reduction) (Cohen 1995) is a variant of the Sequential Covering algorithm. RIPPER is a bit more sophisticated and uses a post-processing phase (rule pruning) to optimize the decision list (or set). RIPPER can run in ordered or unordered mode and generate either a decision list or decision set.
Examples
First, we extract the rules for the penguin sex classification task. The rules plus the default rule are printed in Table 10.6. The interpretation is simple: To predict a new instance, start at the top of the list and check whether a rule applies. If the conditions apply, predict the species on the right-hand side of the rule. If it doesn’t apply, go to the next rule until you have a classification. The default rule ensures that there is always a prediction.
| rules |
|---|
| (body_mass_g <= 3700) and (bill_depth_mm <= 18.5) => sex=F |
| (bill_depth_mm <= 14.8) and (body_mass_g <= 5200) => sex=F |
| (body_mass_g <= 3850) and (bill_length_mm <= 36.9) => sex=F |
| => sex=M |
RIPPER has a specific way of resolving conflicts between rules: it applies them sequentially. This is just one of many general strategies, ranging from rules with the most-specific if-clause to using the rule with the highest precision.
When we use RIPPER on the regression task to predict bike counts, some rules are found. Since RIPPER only works for classification, the bike counts must be turned into a categorical outcome. I achieved this by cutting the bike counts into the quartiles. For example, the interval ([4548, 5956]) covers predicted bike counts between 4548 and 5956. Table 10.7 shows the decision list of learned rules. Interpretation is again: If the conditions apply, we predict the interval on the right-hand side for the number of bikes. I don’t like the decision rules for this example. The nature of the cnt_2d_bfr feature is to adjust for a general trend of bike rentals. cnt and cnt_2d_bfr have a linear relationships which decision rules have a hard time to reflect.
| rules |
|---|
| (cnt_2d_bfr <= 5729) and (cnt_2d_bfr >= 4780) and (temp <= 26) => cnt=(4551,5978.5] |
| (temp >= 14) and (cnt_2d_bfr <= 5515) and (hum <= 63) and (cnt_2d_bfr >= 3574) and (temp <= 27) => cnt=(4551,5978.5] |
| (cnt_2d_bfr >= 3544) and (cnt_2d_bfr <= 3915) and (temp >= 17) and (temp <= 28) => cnt=(4551,5978.5] |
| (cnt_2d_bfr <= 5336) and (cnt_2d_bfr >= 2914) and (weather = GOOD) and (temp >= 7) => cnt=(3193,4551] |
| (cnt_2d_bfr <= 4833) and (cnt_2d_bfr >= 2169) and (hum <= 72) and (workday = Y) => cnt=(3193,4551] |
| (cnt_2d_bfr <= 4097) and (season = WINTER) => cnt=[22,3193] |
| (cnt_2d_bfr <= 4570) and (temp <= 13) => cnt=[22,3193] |
| (hum >= 88) and (season = FALL) => cnt=[22,3193] |
| (cnt_2d_bfr <= 3351) and (cnt_2d_bfr >= 2710) => cnt=[22,3193] |
| => cnt=(5978.5,8714] |
Bayesian Rule Lists
In this section, I’ll show you another approach to learning a decision list, which follows this rough recipe:
- Pre-mine frequent patterns from the data that can be used as conditions for the decision rules.
- Learn a decision list from a selection of the pre-mined rules.
A specific approach using this recipe is called Bayesian Rule Lists (Letham et al. 2015) or BRL for short. BRL uses Bayesian statistics to learn decision lists from frequent patterns which are pre-mined with the FP-tree algorithm (Borgelt 2005).
But let us start slowly with the first step of BRL.
Pre-mining of frequent patterns
A frequent pattern is the frequent (co-)occurrence of feature values. As a pre-processing step for the BRL algorithm, we use the features (we don’t need the target outcome in this step) and extract frequently occurring patterns from them. A pattern can be a single feature value such as size=medium or a combination of feature values such as size=medium AND location=bad.
The frequency of a pattern is measured with its support in the dataset:
\[Support(\mathbf{x}_j=A)=\frac{1}{n}\sum_{i=1}^nI(x^{(i)}_{j}=A)\]
where A is the feature value, n the number of data points in the dataset, and I the indicator function that returns 1 if the feature \(x_j\) of the instance i has level A otherwise 0. In a dataset of house values, if 20% of houses have no balcony and 80% have one or more, then the support for the pattern balcony=0 is 20%. Support can also be measured for combinations of feature values, for example, for balcony=0 AND pets=allowed.
There are many algorithms to find such frequent patterns, for example, Apriori or FP-Growth. Which you use doesn’t matter much; only the speed at which the patterns are found is different, but the resulting patterns are always the same.
I’ll give you a rough idea of how the Apriori algorithm works to find frequent patterns. Actually, the Apriori algorithm consists of two parts, where the first part finds frequent patterns and the second part builds association rules from them. For the BRL algorithm, we are only interested in the frequent patterns that are generated in the first part of Apriori.
In the first step, the Apriori algorithm starts with all feature values that have a support greater than the minimum support defined by the user. If the user says that the minimum support should be 10% and only 5% of the houses have size=big, we would remove that feature value and keep only size=medium and size=small as patterns. This does not mean that the houses are removed from the data; it just means that size=big is not returned as a frequent pattern. Based on frequent patterns with a single feature value, the Apriori algorithm iteratively tries to find combinations of feature values of increasingly higher order. Patterns are constructed by combining feature=value statements with a logical AND, e.g., size=medium AND location=bad. Generated patterns with a support below the minimum support are removed. In the end, we have all the frequent patterns. Any subset of a frequent pattern’s clauses is frequent again, which is called the Apriori property. It makes sense intuitively: By removing a condition from a pattern, the reduced pattern can only cover more or the same number of data points, but not less. For example, if 20% of the houses are size=medium AND location=good, then the support of houses that are only size=medium is 20% or greater. The Apriori property is used to reduce the number of patterns to be inspected. Only in the case of frequent patterns do we have to check patterns of higher order.
Now we are done with pre-mining conditions for the Bayesian Rule List algorithm. But before we move on to the second step of BRL, I would like to hint at another way for rule-learning based on pre-mined patterns. Other approaches suggest including the outcome of interest in the frequent pattern mining process and also executing the second part of the Apriori algorithm that builds IF-THEN rules. Since the algorithm is unsupervised, the THEN-part also contains feature values we are not interested in. But we can filter by rules that have only the outcome of interest in the THEN-part. These rules already form a decision set, but it would also be possible to arrange, prune, delete or recombine the rules.
In the BRL approach however, we work with the frequent patterns and learn the THEN-part and how to arrange the patterns into a decision list using Bayesian statistics.
Learning Bayesian Rule Lists
The goal of the BRL algorithm is to learn an accurate decision list using a selection of the pre-mined conditions while prioritizing lists with few rules and short conditions. BRL addresses this goal by defining a distribution of decision lists with prior distributions for the length of conditions (preferably shorter rules) and the number of rules (preferably a shorter list).
The posterior probability distribution of lists makes it possible to say how likely a decision list is, given assumptions of shortness and how well the list fits the data. Our goal is to find the list that maximizes this posterior probability. Since it is not possible to find the exact best list directly from the distributions of lists, BRL suggests the following recipe: 1) Generate an initial decision list, which is randomly drawn from the prior distribution. 2) Iteratively modify the list by adding, switching, or removing rules, ensuring that the resulting lists follow the posterior distribution of lists. 3) Select the decision list from the sampled lists with the highest probability according to the posterior distribution.
Let’s go over the algorithm more closely: The algorithm starts with pre-mining feature value patterns with the FP-Growth algorithm. BRL makes a number of assumptions about the distribution of the target and the distribution of the parameters that define the distribution of the target. (That’s Bayesian statistics.) If you are unfamiliar with Bayesian statistics, do not get too caught up in the following explanations. It’s important to know that the Bayesian approach is a way to combine existing knowledge or requirements (so-called priori distributions) while also fitting to the data. In the case of decision lists, the Bayesian approach makes sense, since the prior assumptions nudge the decision lists to be short with short rules.
The goal is to sample decision lists d from the posterior distribution:
\[\underbrace{p(d|\mathbf{x},\mathbf{y},A,\alpha,\lambda,\eta)}_{posteriori}\propto\underbrace{p(\mathbf{y}|\mathbf{x},d,\alpha)}_{likelihood}\cdot\underbrace{p(d|A,\lambda,\eta)}_{priori}\]
where d is a decision list, x are the features, y is the target, A the set of pre-mined conditions, \(\lambda\) the prior expected length of the decision lists, \(\eta\) the prior expected number of conditions in a rule, \(\alpha\) the prior pseudo-count for the positive and negative classes which is best fixed at (1,1).
\[p(d|\mathbf{x},\mathbf{y},A,\alpha,\lambda,\eta)\]
quantifies how probable a decision list is, given the observed data and the prior assumptions. This is proportional to the likelihood of the outcome \(Y\) given the decision list and the data times the probability of the list given prior assumptions and the pre-mined conditions.
\[p(\mathbf{y}|\mathbf{x},d,\alpha)\]
is the likelihood of the observed \(y\), given the decision list and the data. BRL assumes that y is generated by a Dirichlet-Multinomial distribution. The better the decision list d explains the data, the higher the likelihood.
\[p(d|A,\lambda,\eta)\]
is the prior distribution of the decision lists. It multiplicatively combines a truncated Poisson distribution (parameter \(\lambda\)) for the number of rules in the list and a truncated Poisson distribution (parameter \(\eta\)) for the number of feature values in the conditions of the rules.
A decision list has a high posterior probability if it explains the outcome y well and is also likely according to the prior assumptions.
Estimations in Bayesian statistics are always a bit tricky because we usually cannot directly calculate the correct answer, but we have to draw candidates, evaluate them, and update our posterior estimates using the Markov chain Monte Carlo method. For decision lists, this is even trickier because we have to draw from the distribution of decision lists. The BRL authors propose to first draw an initial decision list and then iteratively modify it to generate samples of decision lists from the posterior distribution of the lists (a Markov chain of decision lists). The results are potentially dependent on the initial decision list, so it is advisable to repeat this procedure to ensure a great variety of lists. The default in the software implementation is 10 times. The following recipe tells us how to draw an initial decision list:
- Pre-mine patterns with FP-Growth.
- Sample the list length parameter \(m\) from a truncated Poisson distribution.
- For the default rule: Sample the Dirichlet-Multinomial distribution parameter \(\theta_0\) of the target value (i.e., the rule that applies when nothing else applies).
- For decision list rule \(j=1,...,m\), do:
- Sample the rule length parameter \(l\) (number of conditions) for rule \(j\).
- Sample a condition of length \(l_j\) from the pre-mined conditions.
- Sample the Dirichlet-Multinomial distribution parameter for the THEN-part (i.e., for the distribution of the target outcome given the rule).
- For each observation in the dataset:
- Find the rule from the decision list that applies first (top to bottom).
- Draw the predicted outcome from the probability distribution (Binomial) suggested by the rule that applies.
The next step is to generate many new lists starting from this initial sample to obtain many samples from the posterior distribution of decision lists.
The new decision lists are sampled by starting from the initial list and then randomly either moving a rule to a different position in the list or adding a rule to the current decision list from the pre-mined conditions or removing a rule from the decision list. Which of the rules is switched, added, or deleted is chosen at random. At each step, the algorithm evaluates the posterior probability of the decision list (mixture of accuracy and shortness). The Metropolis Hastings algorithm ensures that we sample decision lists that have a high posterior probability. This procedure provides us with many samples from the distribution of decision lists. The BRL algorithm selects the decision list of the samples with the highest posterior probability.
Examples
That’s it with the theory, now let’s see the BRL method in action. The examples use a faster variant of BRL called Scalable Bayesian Rule Lists (SBRL) (Yang, Rudin, and Seltzer 2017). We use the SBRL algorithm to predict the species of the penguins. I had to discretize all input features for the SBRL algorithm to work. To do this, I binned the continuous features based on the frequency of the values by quantiles. We get the rules displayed in Table 10.8.
| rules |
|---|
| If {body_mass_g=[5.1e+03,6.3e+03]} (rule[41]) then p = 0.083 |
| else if {species=Gentoo} (rule[76]) then p = 0.873 |
| else if {body_mass_g=[3.9e+03,5.1e+03)} (rule[40]) then p = 0.066 |
| else if {bill_depth_mm=[15.9,18.7)} (rule[15]) then p = 0.876 |
| else (default rule) then p = 0.333 |
The conditions were selected from patterns that were pre-mined with the FP-Growth algorithm. The following table displays the pool of conditions the SBRL algorithm could choose from for building a decision list. The maximum number of feature values in a condition I allowed as a user was two. Table 10.9 shows a sample of ten patterns.
| pre-mined conditions |
|---|
| species=Gentoo, bill_depth_mm=[13.1, 15.9) |
| body_mass_g=[2.7e+03, 3.9e+03) |
| bill_depth_mm=[13.1, 15.9), bill_length_mm=[41.3, 50.4) |
| bill_length_mm=[41.3, 50.4) |
| flipper_length_mm=[172, 192), body_mass_g=[3.9e+03, 5.1e+03) |
| bill_depth_mm=[15.9, 18.7), flipper_length_mm=[211, 231] |
| species=Adelie |
| species=Adelie, bill_depth_mm=[15.9, 18.7) |
| bill_depth_mm=[18.7, 21.5], flipper_length_mm=[172, 192) |
| species=Adelie, bill_length_mm=[41.3, 50.4) |
Sparsity is king
Fewer and shorter rules make for better model interpretation. But there is a trade-off with complexity and therefore with predictive performance.
Strengths
This section discusses the benefits of IF-THEN rules in general.
IF-THEN rules are easy to interpret. They are probably the most interpretable of the interpretable models. This statement only applies if the number of rules is small, the conditions of the rules are short (maximum 3, I would say), and if the rules are organized in a decision list or a non-overlapping decision set.
Decision rules can be as expressive as decision trees, while being more compact. Decision trees often also suffer from replicated sub-trees, that is, when the splits in a left and a right child node have the same structure.
The prediction with IF-THEN rules is fast since only a few binary statements need to be checked to determine which rules apply.
Decision rules are robust against monotonic transformations of the input features because only the threshold in the conditions changes. They are also robust against outliers since it only matters if a condition applies or not.
IF-THEN rules usually generate sparse models, which means that not many features are included. They select only the relevant features for the model. For example, a linear model assigns a weight to every input feature by default. Features that are irrelevant can simply be ignored by IF-THEN rules.
Simple rules, like from OneR, can be used as a baseline for more complex algorithms.
Limitations
This section deals with the disadvantages of IF-THEN rules in general.
The research and literature for IF-THEN rules focuses on classification and almost completely neglects regression. While you can always divide a continuous target into intervals and turn it into a classification problem, you always lose information. In general, approaches are more attractive if they can be used for both regression and classification.
Often the features also have to be categorical. That means numeric features must be categorized if you want to use them. There are many ways to cut a continuous feature into intervals, but this is not trivial and comes with many questions without clear answers. How many intervals should the feature be divided into? What’s the splitting criterion: Fixed interval lengths, quantiles, or something else? Categorizing continuous features is a non-trivial issue that is often neglected, and people just use the next best method (like I did in the examples).
Many of the older rule-learning algorithms are prone to overfitting. The algorithms presented here all have at least some safeguards to prevent overfitting: OneR is limited because it can only use one feature (only problematic if the feature has too many levels or if there are many features, which equates to the multiple testing problem), RIPPER does pruning and Bayesian Rule Lists impose a prior distribution on the decision lists.
Decision rules are bad at describing linear relationships between features and output. That’s a problem they share with decision trees. Decision trees and rules can only produce step-like prediction functions, where changes in the prediction are always discrete steps and never smooth curves. This is related to the issue that the inputs have to be categorical. In decision trees, they are implicitly categorized by splitting them.
Software and alternatives
OneR is implemented in the R package OneR, which was used for the examples in this book. OneR is also implemented in the Weka machine learning library and, as such, is available in Java, R, and Python. RIPPER is also implemented in Weka. For the examples, I used the R implementation of JRIP in the RWeka package. SBRL is available as an R package (which I used for the examples), in Python, or as a C implementation. Additionally, I recommend the imodels package, which implements rule-based models such as Bayesian rule lists, CORELS, OneR, greedy rule lists, and more in a Python package with a unified scikit-learn interface.
I will not even try to list all alternatives for learning decision rule sets and lists, but will point to some summarizing work. I recommend the book “Foundations of Rule Learning” by Fürnkranz, Gamberger, and Lavrač (2012). It’s an extensive work on learning rules, for those who want to dive deeper into the topic. It provides a holistic framework for thinking about learning rules and presents many rule learning algorithms. I also recommend checking out the Weka rule learners, which implement RIPPER, M5Rules, OneR, PART, and many more. IF-THEN rules can be used in linear models as described in this book in the chapter about the RuleFit algorithm.