31 Influential Instances
Machine learning models are ultimately a product of training data, and deleting one of the training instances can affect the resulting model. We call a training instance “influential” when its deletion from the training data considerably changes the parameters or predictions of the model. By identifying influential training instances, we can “debug” machine learning models and better explain their behaviors and predictions.
This chapter shows you two approaches for identifying influential instances, namely deletion diagnostics and influence functions. Both approaches are based on robust statistics, which provide statistical methods that are less affected by outliers or violations of model assumptions. Robust statistics also provide methods to measure how robust estimates from data are (such as a mean estimate or the weights of a prediction model).
Imagine you want to estimate the average income of the people in your city and ask ten random people on the street how much they earn. Apart from the fact that your sample is probably really bad, how much can your average income estimate be influenced by a single person? To answer this question, you can recalculate the mean value by omitting individual answers or derive mathematically via “influence functions” how the mean value can be influenced. With the deletion approach, we recalculate the mean value ten times, omitting one of the income statements each time, and measure how much the mean estimate changes. A big change means that an instance was very influential. The second approach upweights one of the persons by an infinitesimally small weight, which corresponds to the calculation of the first derivative of a statistic or model. This approach is also known as the “infinitesimal approach” or “influence function.” The answer is, by the way, that your mean estimate can be very strongly influenced by a single answer, since the mean scales linearly with single values. A more robust choice is the median (the value at which one half of people earn more and the other half less), because even if the person with the highest income in your sample would earn ten times more, the resulting median would not change.
Deletion diagnostics and influence functions can also be applied to the parameters or predictions of machine learning models to understand their behavior better or to explain individual predictions. Before we look at these two approaches for finding influential instances, we will examine the difference between an outlier and an influential instance.
Outlier
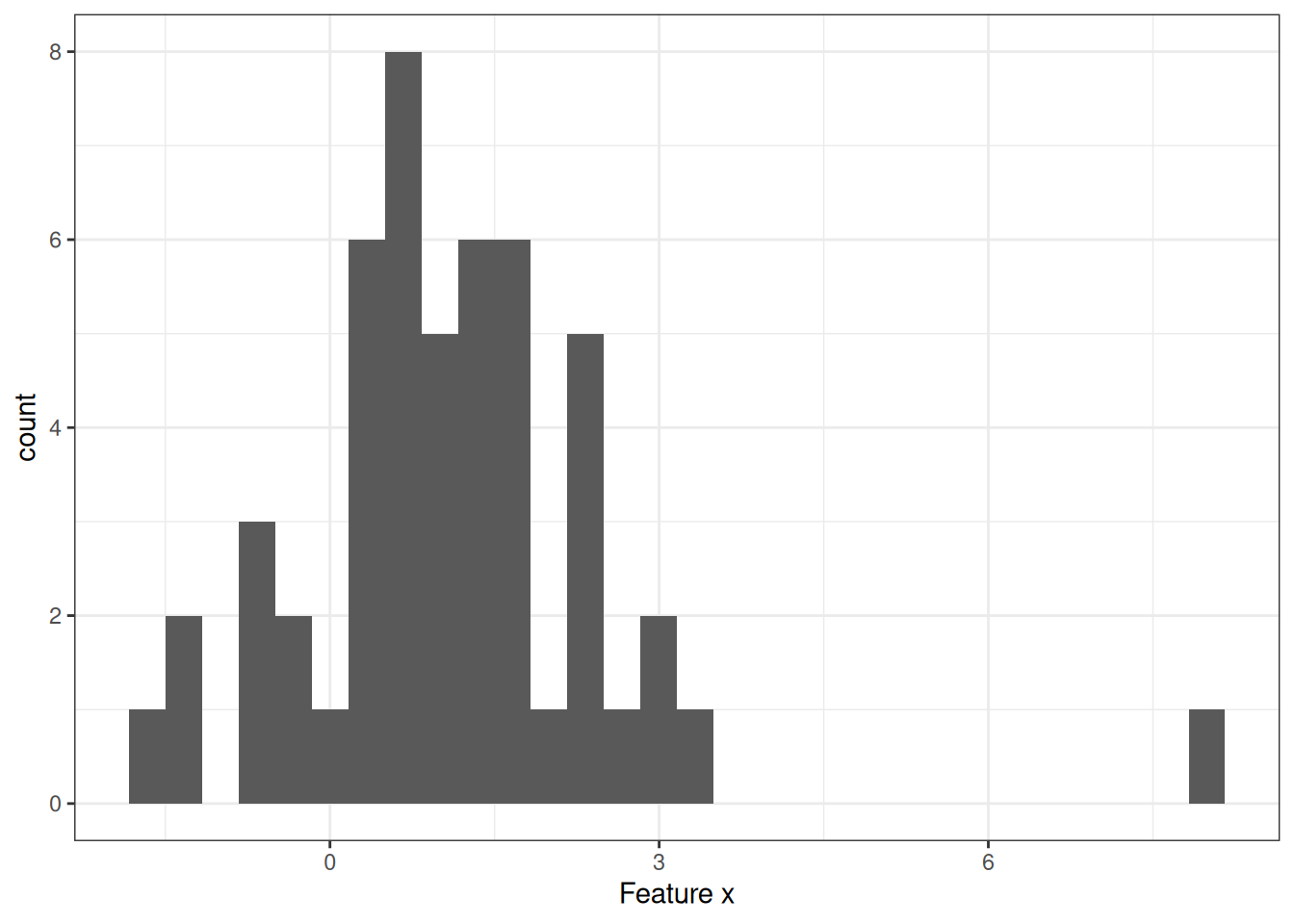
An outlier is an instance that is far away from the other instances in the dataset. “Far away” means that the distance, for example, the Euclidean distance, to all the other instances is very large. In a dataset of newborns, a newborn weighing 5 kg would be considered an outlier. In a dataset of bank accounts with mostly checking accounts, a dedicated loan account (large negative balance, few transactions) would be considered an outlier. Figure 31.1 shows an outlier for a 1-dimensional distribution.
Outliers can be interesting data points (e.g., criticisms). When an outlier influences the model, it’s also an influential instance.
Influential instance
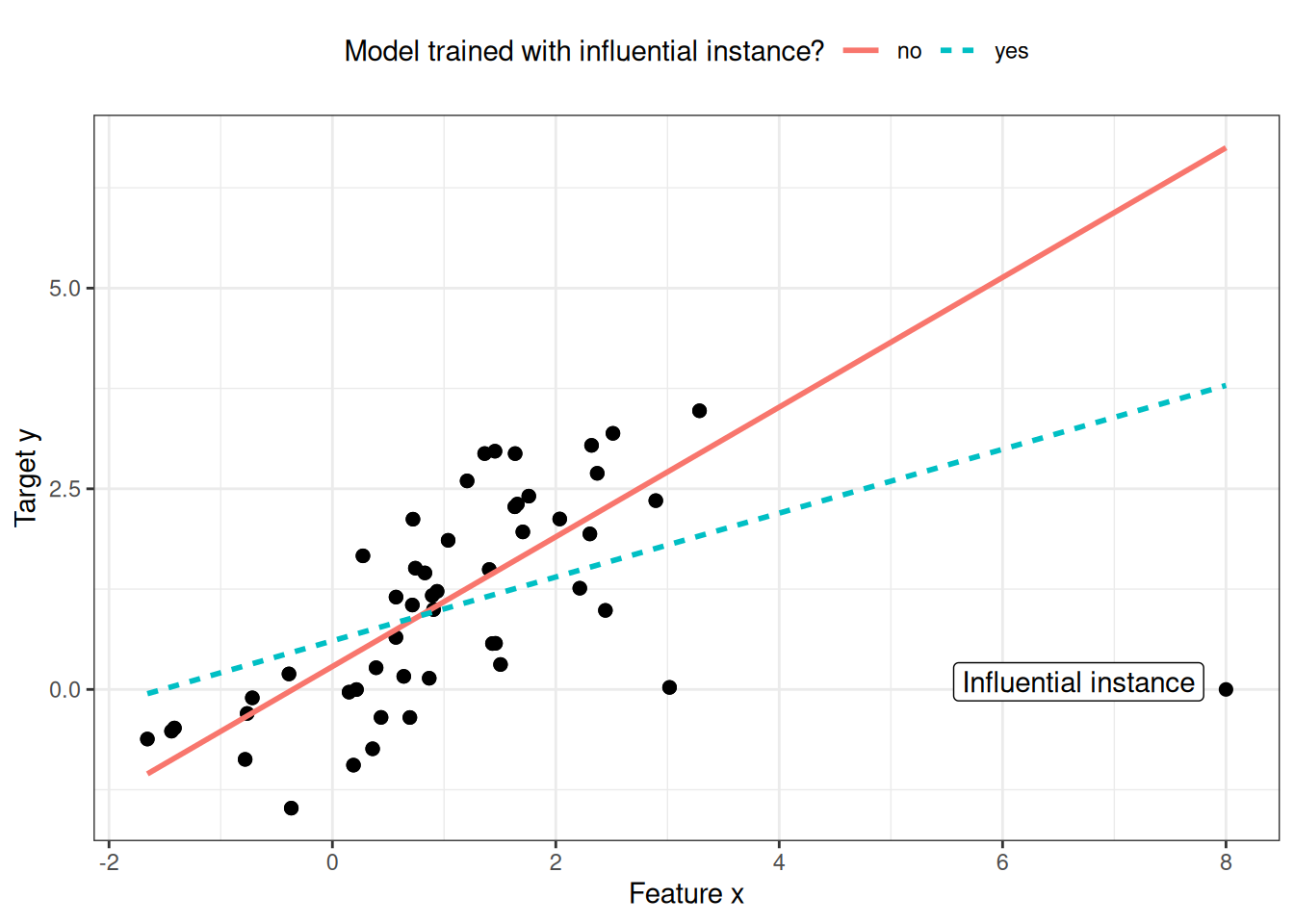
An influential instance is a data instance whose removal has a strong effect on the trained model. The more the model parameters or predictions change when the model is retrained with a particular instance removed from the training data, the more influential that instance is. Whether an instance is influential for a trained model also depends on its value for the target y. Figure 31.2 shows an influential instance for a linear regression model.
Why do influential instances help to understand the model?
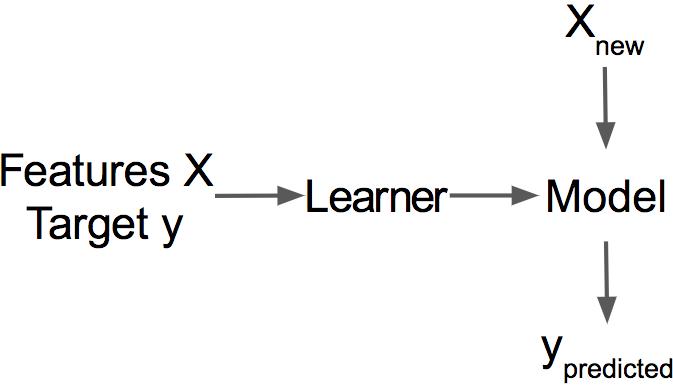
The key idea behind influential instances for interpretability is to trace model parameters and predictions back to where it all began: the training data. A learner, that is, the algorithm that generates the machine learning model, is a function that takes training data consisting of features \(\mathbf{X}\) and target vector \(\mathbf{y}\) and generates a machine learning model, see also Figure 31.3. For example, the learner of a decision tree is an algorithm that selects the split features and the values at which to split. A learner for a neural network uses backpropagation to find the best weights.
We ask how the model parameters or the predictions would change if we removed instances from the training data in the training process. This is in contrast to other interpretability approaches that analyze how the prediction changes when we manipulate the features of the instances to be predicted, such as partial dependence plots or feature importance. With influential instances, we don’t treat the model as fixed, but as a function of the training data. Influential instances help us answer questions about global model behavior and about individual predictions. Which were the most influential instances for the model parameters or the predictions overall? Which were the most influential instances for a particular prediction? Influential instances tell us for which instances the model could have problems, which training instances should be checked for errors, and give an impression of the robustness of the model. We might not trust a model if a single instance has a strong influence on the model predictions and parameters. At least that would make us investigate further.
How can we find influential instances? We have two ways of measuring influence: Our first option is to delete the instance from the training data, retrain the model on the reduced training dataset and observe the difference in the model parameters or predictions (either individually or over the complete dataset). The second option is to upweight a data instance by approximating the parameter changes based on the gradients of the model parameters. The deletion approach is easier to understand and motivates the upweighting approach, so we start with the former.
Deletion Diagnostics
Statisticians have already done a lot of research in the area of influential instances, especially for (generalized) linear regression models. When you search for “influential observations,” the first search results are about measures like DFBETA and Cook’s distance. DFBETA measures the effect of deleting an instance on the model parameters. Cook’s distance (Cook 1977) measures the effect of deleting an instance on model predictions. For both measures, we have to retrain the model repeatedly, omitting individual instances each time. The parameters or predictions of the model with all instances are compared with the parameters or predictions of the model with one of the instances deleted from the training data.
DFBETA is defined as:
\[DFBETA_{i}=\boldsymbol{\beta}-\boldsymbol{\beta}^{(-i)}\]
where \(\boldsymbol{\beta}\) is the weight vector when the model is trained on all data instances, and \(\boldsymbol{\beta^{(-i)}}\) is the weight vector when the model is trained without instance \(i\). Quite intuitive, I would say. DFBETA works only for models with weight parameters, such as logistic regression or neural networks, but not for models such as decision trees, tree ensembles, some support vector machines, and so on.
Cook’s distance was invented for linear regression models, and approximations for generalized linear regression models exist. Cook’s distance for a training instance is defined as the (scaled) sum of the squared differences in the predicted outcome when the i-th instance is removed from the model training.
\[D_i=\frac{\sum_{j=1}^n(\hat{y}_j-\hat{y}_{j}^{(-i)})^2}{p\cdot{}MSE}\]
where the numerator is the squared difference between the prediction of the model with and without the i-th instance, summed over the dataset. The denominator is the number of features p times the mean squared error. The denominator is the same for all instances, no matter which instance i is removed. Cook’s distance tells us how much the predicted output of a linear model changes when we remove the i-th instance from the training.
Can we use Cook’s distance and DFBETA for any machine learning model? DFBETA requires model parameters, so this measure works only for parameterized models. Cook’s distance doesn’t require any model parameters. Interestingly, Cook’s distance is usually not seen outside the context of linear models and generalized linear models, but the idea of taking the difference between model predictions before and after the removal of a particular instance is very general. A problem with the definition of Cook’s distance is the MSE, which is not meaningful for all types of prediction models (e.g., classification).
The simplest influence measure for the effect on the model predictions can be written as follows:
\[\text{Influence}^{(-i)}=\frac{1}{n}\sum_{k=1}^{n}\left|\hat{y}_k-\hat{y}_{k}^{(-i)}\right|\]
This expression is basically the numerator of Cook’s distance, with the difference that the absolute difference is added up instead of the squared differences. This was a choice I made because it makes sense for the examples later. The general form of deletion diagnostic measures consists of choosing a measure (such as the predicted outcome) and calculating the difference of the measure for the model trained on all instances and when the instance is deleted.
We can easily break the influence down to explain for the prediction of instance k what the influence of the i-th training instance was:
\[\text{Influence}_{k}^{(-i)}=\left|\hat{y}_k - \hat{y}_{k}^{(-i)}\right|\]
This would also work for the difference in model parameters or the difference in the loss. In the following example, we will use these simple influence measures.
Deletion diagnostics example
In the following example, we train a random forest to predict whether a penguin’s sex given body measurements and measure which training instances were most influential overall and for a particular prediction. Since this is a classification problem, we measure the influence as the difference in predicted probability for female. An instance is influential if the predicted probability strongly increases or decreases on average in the dataset when the instance is removed from model training. Measuring influence for all 222 training instances requires training the model once on all data and retraining it 222 times (= size of training data) with one of the instances removed each time.
The most influential instance has an influence measure of about 0.012. An influence of 0.012 means that if we remove the 12-th instance, the predicted probability changes by 1.2 percentage point on average. This doesn’t sound like much, but it’s an average over the entire data coming from just removing 1 data point. Now we know which of the data instances were most influential for the model. This is already useful to know for debugging the data. Is there a problematic instance? Are there measurement errors? The influential instances are the first ones that should be checked for errors because each error in them strongly influences the model predictions.
Review the most influential data
For debugging, review the most influential instances first, so you effectively use your time on the data that matters the most for predictions.
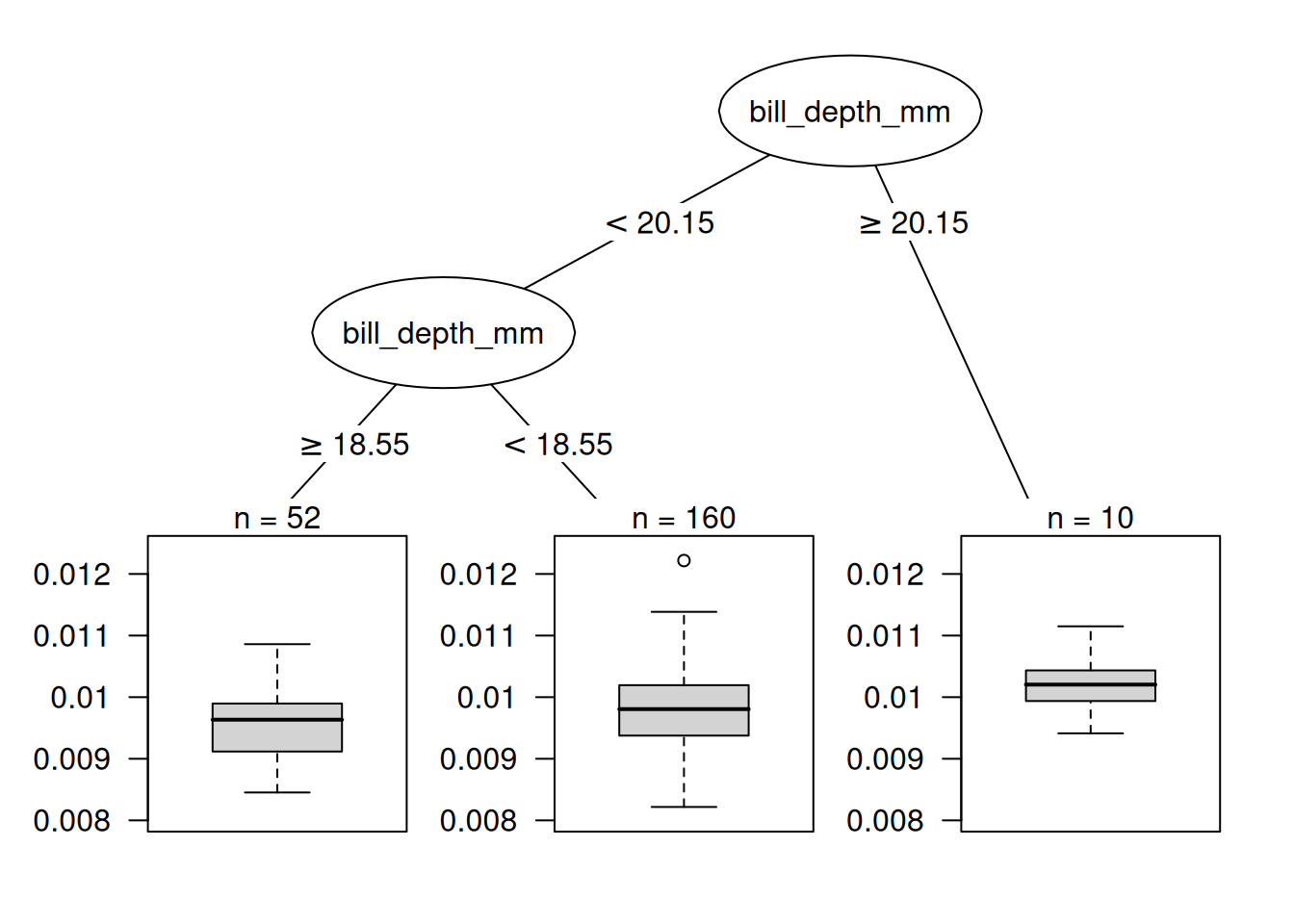
Apart from model debugging, can we learn something to better understand the model? Just printing out the top 10 most influential instances is not very useful, because it is just a table of instances with many features. All methods that return instances as output only make sense if we have a good way of representing them. But we can better understand what kind of instances are influential when we ask: What distinguishes an influential instance from a non-influential instance? We can turn this question into a regression problem and model the influence of an instance as a function of its feature values. We are free to choose any interpretable model. For this example, I chose a decision tree (Figure 31.4) that shows that data from penguins with deep bills were the most influential for the support vector machine.
This first influence analysis revealed the overall most influential instance. Now we select one of the instances, namely the 8-th instance, for which we want to explain the prediction by finding the most influential training data instances. It’s like a counterfactual question: How would the prediction for instance 8 change if we omit instance i from the training process? We repeat this removal for all instances. Then we select the training instances that result in the biggest change in the prediction of instance 8 when they are omitted from the training, and use them to explain the prediction of the model for that instance. We could return the, say, top 10 most influential instances for predicting the 8-th instance printed as a table. Not very useful, because we could not see much. Again, it makes more sense to find out what distinguishes the influential instances from the non-influential instances by analyzing their features. We use a decision tree trained to predict the influence given the features, but in reality we misuse it only to find a structure and not to actually predict something. The decision tree in Figure 31.5 shows which kind of training instances were most influential for predicting the 8-th instance. Data from penguins with a high body mass and deep bills had a larger influence on the prediction of the 8-th instance.
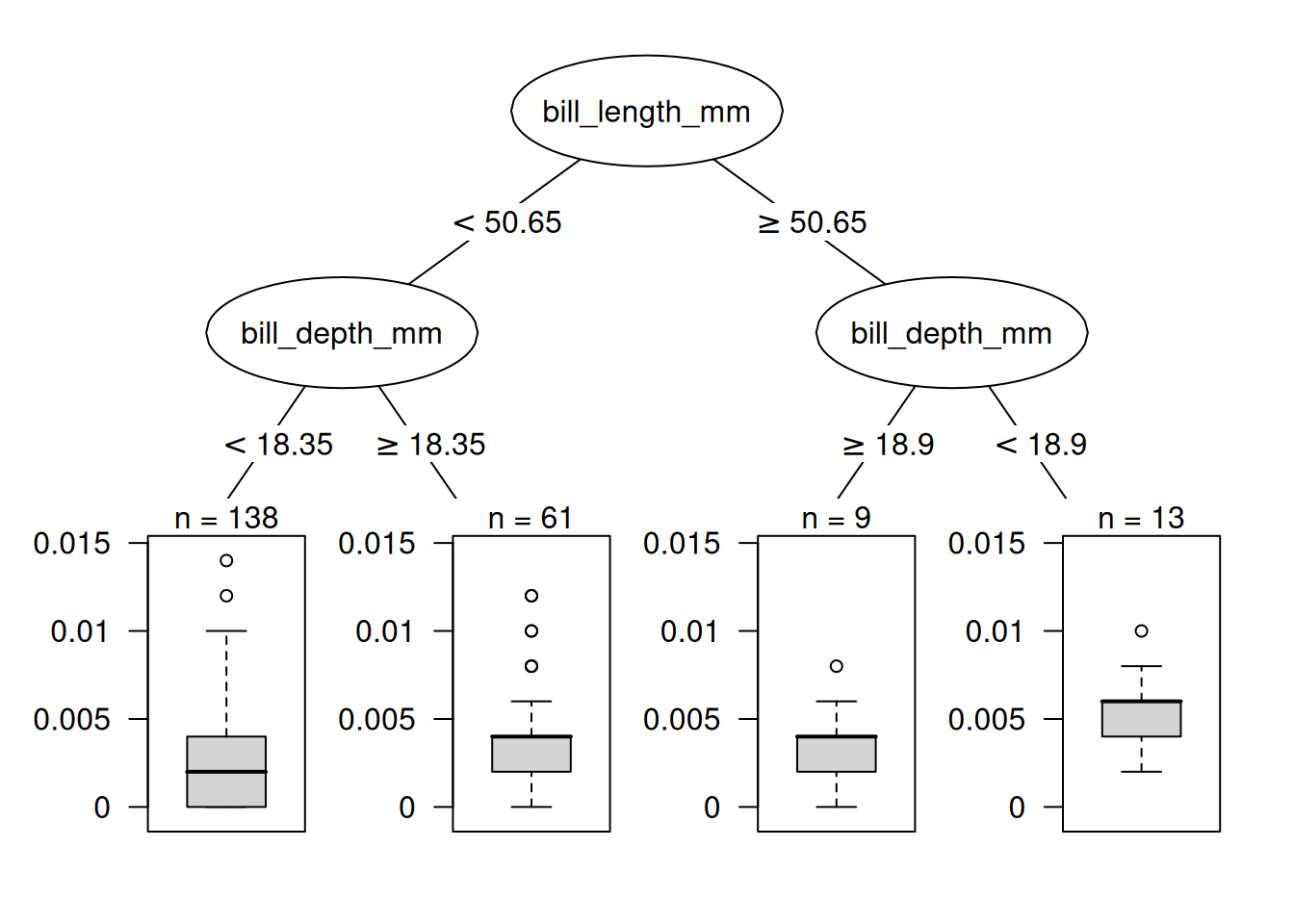
These examples showed how useful it is to identify influential instances to check the robustness of the model. One problem with the proposed approach is that the model needs to be retrained for each training instance. The whole retraining can be quite slow, because if you have thousands of training instances, you will have to retrain your model thousands of times. Assuming the model takes one day to train and you have 1,000 training instances, then the computation of influential instances – without parallelization – will take almost 3 years. Nobody has time for this. In the rest of this chapter, I’ll show you a method that does not require retraining the model.
Influence Functions
You: I want to know the influence a training instance has on a particular prediction.
Research: You can delete the training instance, retrain the model, and measure the difference in the prediction.
You: Great! But do you have a method for me that works without retraining? It takes so much time.
Research: Do you have a model with a loss function that is twice differentiable with respect to its parameters?
You: I trained a neural network with the logistic loss. So, yes.
Research: Then you can approximate the influence of the instance on the model parameters and on the prediction with influence functions. The influence function is a measure of how strongly the model parameters or predictions depend on a training instance. Instead of deleting the instance, the method upweights the instance in the loss by a very small step. This method involves approximating the loss around the current model parameters using the gradient and Hessian matrix. Loss upweighting is similar to deleting the instance.
You: Great, that’s what I’m looking for!
Koh and Liang (2017) suggested using influence functions, a method of robust statistics, to measure how an instance influences model parameters or predictions. As with deletion diagnostics, the influence functions trace the model parameters and predictions back to the responsible training instance. However, instead of deleting training instances, the method approximates how much the model changes when the instance is upweighted in the empirical risk (sum of the loss over the training data).
The method of influence functions requires access to the loss gradient with respect to the model parameters (or with respect to the predictions), which only works for a subset of machine learning models. Logistic regression, neural networks, and support vector machines qualify; tree-based methods like random forests do not. Influence functions help to understand the model behavior, debug the model, and detect errors in the dataset.
The following section explains the intuition and math behind influence functions.
Math behind influence functions
The key idea behind influence functions is to upweight the loss of a training instance by an infinitesimally small step \(\epsilon\), which results in new model parameters:
\[\hat{\boldsymbol{\theta}}_{\epsilon, \mathbf{z}} = \arg\min_{\boldsymbol{\theta} \in \Theta} \left(\frac{1}{n}\sum_{i=1}^n L(\mathbf{z}^{(i)}, \boldsymbol{\theta}) + \epsilon L(\mathbf{z}, \boldsymbol{\theta}) \right)\]
where \(\theta\) is the model parameter vector and \(\hat{\boldsymbol{\theta}}_{\epsilon, \mathbf{z}}\) is the parameter vector after upweighting \(\mathbf{z}\) by a very small number \(\epsilon\). \(L\) is the loss function with which the model was trained, \(\mathbf{z}^{(i)}\) is the training data, and \(\mathbf{z}\) is the training instance that we want to upweight to simulate its removal. The intuition behind this formula is: How much will the loss change if we upweight a particular instance \(\mathbf{z}^{(i)}\) from the training data by a little (\(\epsilon\)) and downweight the other data instances accordingly? What would the parameter vector look like to optimize this new combined loss? The influence function of the parameters, i.e., the influence of upweighting training instance \(\mathbf{z}\) on the parameters, can be calculated as follows.
\[I_{\text{up,params}}(\mathbf{z}) = \left.\frac{d \hat{\boldsymbol{\theta}}_{\epsilon, \mathbf{z}}}{d\epsilon}\right|_{\epsilon=0} = -H_{\hat{\boldsymbol{\theta}}}^{-1} \nabla_{\boldsymbol{\theta}} L(\mathbf{z}, \hat{\boldsymbol{\theta}})\]
The last expression \(\nabla_{\boldsymbol{\theta}}L(\mathbf{z}, \hat{\boldsymbol{\theta}})\) is the loss gradient with respect to the parameters for the upweighted training instance. The gradient is the rate of change of the loss of the training instance. It tells us how much the loss changes when we change the model parameters \(\hat{\boldsymbol{\theta}}\) by a bit. A positive entry in the gradient vector means that a small increase in the corresponding model parameter increases the loss; a negative entry means that the increase of the parameter reduces the loss. The first part \(H^{-1}_{\hat{\boldsymbol{\theta}}}\) is the inverse Hessian matrix (second derivative of the loss with respect to the model parameters). The Hessian matrix is the rate of change of the gradient, or expressed as loss, it is the rate of change of the rate of change of the loss. It can be estimated using:
\[H_{\boldsymbol{\theta}} = \frac{1}{n}\sum_{i=1}^n \nabla^2_{\hat{\boldsymbol{\theta}}}L(\mathbf{z}^{(i)}, \hat{\boldsymbol{\theta}})\]
More informally: The Hessian matrix records how curved the loss is at a certain point. The Hessian is a matrix and not just a vector because it describes the curvature of the loss, and the curvature depends on the direction in which we look. The actual calculation of the Hessian matrix is time-consuming if you have many parameters. Koh and Liang suggested some tricks to calculate it efficiently, which goes beyond the scope of this chapter. Updating the model parameters, as described by the above formula, is equivalent to taking a single Newton step after forming a quadratic expansion around the estimated model parameters.
What intuition is behind this influence function formula? The formula comes from forming a quadratic expansion around the parameters \(\hat{\boldsymbol{\theta}}\). That means we do not actually know, or it is too complex to calculate how exactly the loss of instance \(\mathbf{z}\) will change when it is removed/upweighted. We approximate the function locally by using information about the steepness (= gradient) and the curvature (= Hessian matrix) at the current model parameter setting. With this loss approximation, we can calculate what the new parameters would approximately look like if we upweighted instance \(\mathbf{z}\):
\[\hat{\boldsymbol{\theta}}_{-\mathbf{z}} \approx \hat{\boldsymbol{\theta}} - \frac{1}{n} I_{\text{up,params}}(\mathbf{z})\]
The approximate parameter vector is basically the original parameter minus the gradient of the loss of \(\mathbf{z}\) (because we want to decrease the loss) scaled by the curvature (= multiplied by the inverse Hessian matrix) and scaled by \(\frac{1}{n}\) because that is the weight of a single training instance.
Figure 31.6 shows how the upweighting works. The x-axis shows the value of the \(\boldsymbol{\theta}\) parameter and the y-axis the corresponding value of the loss with upweighted instance \(\mathbf{z}\). The model parameter here is 1-dimensional for demonstration purposes, but in reality, it is usually high-dimensional. We move only \(\frac{1}{n}\) in the direction of improvement of the loss for instance \(\mathbf{z}\). We do not know how the loss would really change when we delete \(\mathbf{z}\), but with the first and second derivatives of the loss, we create this quadratic approximation around our current model parameter and pretend that this is how the real loss would behave.
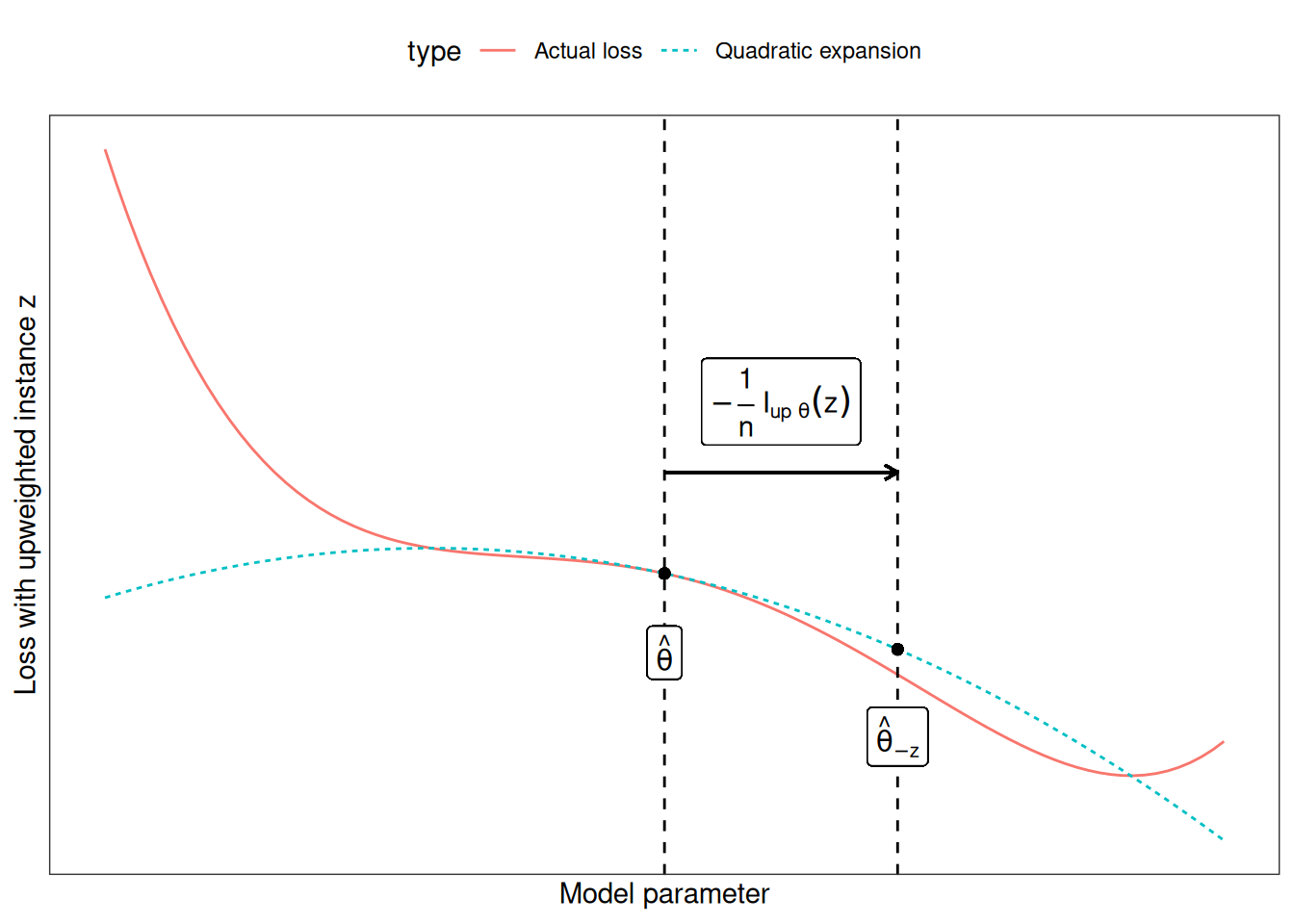
We do not actually need to calculate the new parameters, but we can use the influence function as a measure of the influence of \(\mathbf{z}\) on the parameters.
How do the predictions change when we upweight training instance \(\mathbf{z}\)? We can either calculate the new parameters and then make predictions using the newly parameterized model, or we can also calculate the influence of instance \(\mathbf{z}\) on the predictions directly, since we can calculate the influence by using the chain rule:
\[\begin{align*} I_{up,loss}(\mathbf{z}, \mathbf{z}_{test}) & = \left.\frac{d L(\mathbf{z}_{test},\hat{\boldsymbol{\theta}}_{\epsilon, \mathbf{z}})}{d\epsilon}\right|_{\epsilon=0} \\ & = \left.\nabla_{\boldsymbol{\theta}}L(\mathbf{z}_{test},\hat{\boldsymbol{\theta}})^T \frac{d\hat{\boldsymbol{\theta}}_{\epsilon,\mathbf{z}}}{d \epsilon}\right|_{\epsilon=0} \\ & = -\nabla_{\boldsymbol{\theta}}L(\mathbf{z}_{test}, \hat{\boldsymbol{\theta}})^T H^{-1}_{\boldsymbol{\theta}} \nabla_{\boldsymbol{\theta}} L(\mathbf{z},\hat{\boldsymbol{\theta}}) \end{align*}\]
The first line of this equation means that we measure the influence of a training instance on a certain prediction \(\mathbf{z}_{test}\) as a change in loss of the test instance when we upweight the instance \(\mathbf{z}\) and get new parameters \(\hat{\theta}_{\epsilon,z}\). For the second line of the equation, we have applied the chain rule of derivatives and get the derivative of the loss of the test instance with respect to the parameters times the influence of z on the parameters. In the third line, we replace the expression with the influence function for the parameters. The first term in the third line \(\nabla_{\boldsymbol{\theta}} L(\mathbf{z}_{test},\hat{\boldsymbol{\theta}})^T\) is the gradient of the test instance with respect to the model parameters.
Having a formula is great and the scientific and accurate way of showing things. But I think it is very important to get some intuition about what the formula means. The formula for \(I_{\text{up,loss}}\) states that the influence function of the training instance \(\mathbf{z}\) on the prediction of an instance \(\mathbf{z}_{test}\) is “how strongly the instance reacts to a change of the model parameters” multiplied by “how much the parameters change when we upweight the instance \(\mathbf{z}\)”. Another way to read the formula: The influence is proportional to how large the gradients for the training and test loss are. The higher the gradient of the training loss, the higher its influence on the parameters and the higher the influence on the test prediction. The higher the gradient of the test prediction, the more influenceable the test instance. The entire construct can also be seen as a measure of the similarity (as learned by the model) between the training and the test instance.
That’s it with theory and intuition. The next section explains how influence functions can be applied.
Application of Influence Functions
Influence functions have many applications, some of which have already been presented in this chapter.
Understanding model behavior
Different machine learning models have different ways of making predictions. Even if two models have the same performance, the way they make predictions from the features can be very different, and therefore fail in different scenarios. Understanding the particular weaknesses of a model by identifying influential instances helps to form a “mental model” of the machine learning model behavior in your mind.
Handling domain mismatches / Debugging model errors
Handling domain mismatch is closely related to better understanding the model behavior. Domain mismatch means that the distribution of training and test data is different, which can cause the model to perform poorly on the test data. Influence functions can identify training instances that caused the error. Suppose you have trained a prediction model for the outcome of patients who have undergone surgery. All these patients come from the same hospital. Now you use the model in another hospital and see that it does not work well for many patients. Of course, you assume that the two hospitals have different patients, and if you look at their data, you can see that they differ in many features. But what are the features or instances that have “broken” the model? Here too, influential instances are a good way to answer this question. You take one of the new patients, for whom the model has made a false prediction, find and analyze the most influential instances. For example, this could show that the second hospital has older patients on average, and the most influential instances from the training data are the few older patients from the first hospital, and the model simply lacked the data to learn to predict this subgroup well. The conclusion would be that the model needs to be trained on more patients who are older in order to work well in the second hospital.
Fixing training data
If you have a limit on how many training instances you can check for correctness, how do you make an efficient selection? The best way is to select the most influential instances, because – by definition – they have the most influence on the model. Even if you would have an instance with obviously incorrect values, if the instance is not influential and you only need the data for the prediction model, it is a better choice to check the influential instances. For example, you train a model for predicting whether a patient should remain in the hospital or be discharged early. You really want to make sure that the model is robust and makes correct predictions, because a wrong release of a patient can have bad consequences. Patient records can be very messy, so you do not have perfect confidence in the quality of the data. But checking patient information and correcting it can be very time-consuming, because once you have reported which patients you need to check, the hospital actually needs to send someone to look at the records of the selected patients more closely, which might be handwritten and lying in some archive. Checking data for a patient could take an hour or more. In view of these costs, it makes sense to check only a few important data instances. The best way is to select patients who have had a high influence on the prediction model. Koh and Liang (2017) showed that this type of selection works much better than random selection or the selection of those with the highest loss or wrong classification.
Strengths
The approaches of deletion diagnostics and influence functions are very different from feature-perturbation based approaches like SHAP. A look at influential instances emphasizes the role of training data in the learning process. This makes influence functions and deletion diagnostics one of the best debugging tools for machine learning models. Of the techniques presented in this book, they are the only ones that directly help to identify the instances which should be checked for errors.
Deletion diagnostics are model-agnostic, meaning the approach can be applied to any model. Also, influence functions based on the derivatives can be applied to a broad class of models.
We can use these methods to compare different machine learning models and better understand their different behaviors, going beyond comparing only the predictive performance.
We have not talked about this topic in this chapter, but influence functions via derivatives can also be used to create adversarial training data. These are instances that are manipulated in such a way that the model cannot predict certain test instances correctly when the model is trained on those manipulated instances. The difference to the methods in the Adversarial Examples chapter is that the attack takes place during training time, also known as poisoning attacks. If you are interested, read the paper by Koh and Liang (2017).
For deletion diagnostics and influence functions, we considered the difference in the prediction and for the influence function the increase of the loss. But, really, the approach is generalizable to any question of the form: “What happens to … when we delete or upweight instance \(\mathbf{z}\)?”, where you can fill “…” with any function of your model of your desire. You can analyze how much a training instance influences the overall loss of the model. You can analyze how much a training instance influences the feature importance. You can analyze how much a training instance influences which feature is selected for the first split when training a decision tree.
It’s also possible to identify groups of influential instances (Koh et al. 2019).
Limitations
Deletion diagnostics are very expensive to calculate because they require retraining. But history has shown that computer resources are constantly increasing. A calculation that 20 years ago was unthinkable in terms of resources can easily be performed with your smartphone. You can train models with thousands of training instances and hundreds of parameters on a laptop in seconds/minutes. It’s therefore not a big leap to assume that deletion diagnostics will work without problems even with large neural networks in 10 years.
Influence functions are a good alternative to deletion diagnostics, but only for models with a 2nd order differentiable loss function with respect to its parameters, such as neural networks. They do not work for tree-based methods like random forests, boosted trees, or decision trees. Even if you have models with parameters and a loss function, the loss may not be differentiable. But for the last problem, there is a trick: Use a differentiable loss as a substitute for calculating the influence when, for example, the underlying model uses the Hinge loss instead of some differentiable loss. The loss is replaced by a smoothed version of the problematic loss for the influence functions, but the model can still be trained with the non-smooth loss.
Influence functions are only approximate, because the approach forms a quadratic expansion around the parameters. The approximation can be wrong, and the influence of an instance is actually higher or lower when removed. Koh and Liang (2017) showed for some examples that the influence calculated by the influence function was close to the influence measure obtained when the model was actually retrained after the instance was deleted. But there is no guarantee that the approximation will always be so close.
There’s no clear cutoff of the influence measure at which we call an instance influential or non-influential. It’s useful to sort the instances by influence, but it would be great to have the means not only to sort the instances but actually to distinguish between influential and non-influential. For example, if you identify the top 10 most influential training instances for a test instance, some of them may not be influential because, for example, only the top 3 were really influential.
Software and Alternatives
Deletion diagnostics are very simple to implement.
For linear models and generalized linear models, many influence measures, like Cook’s distance, are implemented in R in the stats package.
Koh and Liang published the Python code for influence functions from their paper in a repository. That’s great! Unfortunately, it’s “only” the code of the paper and not a maintained and documented Python module. The code is focused on the TensorFlow library, so you cannot use it directly for black box models using other frameworks, like scikit-learn.